
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
RFC 9750: The Messaging Layer Security (MLS) Architecture
Date de publication du RFC : Avril 2025
Auteur(s) du RFC : B. Beurdouche (Inria & Mozilla), E. Rescorla (Windy Hill Systems), E. Omara, S. Inguva, A. Duric (Wire)
Pour information
Réalisé dans le cadre du groupe de travail IETF mls
Première rédaction de cet article le 23 avril 2025
On le sait, un des problèmes stratégiques de l'Internet est l'absence d'un protocole de messagerie instantanée standard et largement répandu. Autant le courrier électronique fonctionne relativement bien entre logiciels différents, autant la messagerie instantanée est un monde de jardins clos, incompatibles entre eux, et qui nécessite d'installer vingt applications différentes sur son ordiphone. L'interopérabilité reste un objectif lointain. Il n'y a pas de solution simple à ce problème mais le système MLS (Messaging Layer Security) vise à au moins fournir un mécanisme de sécurité pour les groupes, mécanisme qui peut ensuite être utilisé par un protocole complet, comme XMPP (RFC 6120). MLS est normalisé dans le RFC 9420 et cet autre RFC, le RFC 9750, décrit l'architecture générale.
Les services de sécurité que doit offrir MLS sont les classiques (confidentialité, notamment) et, bien sûr, doivent être assurés de bout en bout (l'opérateur du service ne doit pas pouvoir casser la sécurité et, par exemple, ne doit pas pouvoir lire les messages). Quand il n'y a que deux participants, c'est relativement facile mais MLS est prévu pour des groupes, allant de deux à potentiellement des centaines de milliers de participant·es.
Le protocole, on l'a vu, est spécifié dans le RFC 9420. Il repose sur l'envoi de messages de maintenance du
groupe, comme le message Proposal, qui demande
un changement dans la composition du groupe, ou
Commit, qui va créer une nouvelle
epoch, c'est-à-dire un nouvel état du groupe (la
ressemblance avec le commit d'un VCS comme
git est volontaire). Les clés effectivement
utilisées pour le chiffrement sont liées à cet état, et changent
avec lui.
Le protocole MLS repose sur deux services, qui doivent être fournis pour qu'il puisse fonctionner (voir aussi la section 7) :
- Un service d'authentification des utilisateurices, l'AS (Authentication Service, section 4 du RFC), qui permettre d'obtenir les clés publiques, avec la garantie qu'elles sont bien liées à l'identificateur utilisé par l'utilisateurice,
- Un service de livraison, le DS (Delivery Service, section 5), qui va se charger de porter les messages.
Il n'y a pas besoin de faire confiance au DS, tous les messages étant chiffrés. La seule possibilité d'action d'un DS malveillant serait de ne pas transmettre les messages. (Par contre, un AS malveillant pourrait casser toute la sécurité, en envoyant des clés publiques mensongères, permettant par exemple l'espionnage.)
MLS n'impose pas une forme particulière à l'AS et au DS. Par exemple, il pourrait utiliser une PKI (RFC 5280) traditionnelle comme AS. On l'a dit, MLS n'est pas une solution complète de messagerie instantanée, une telle solution nécessite aussi l'AS, le DS et plein d'autres choses. Parmi les systèmes existants, on peut noter que PGP repose sur les serveurs de clés et le Web of Trust comme AS et sur le courrier comme DS. Signal repose sur un système centralisé comme DS et sur une vérification des clés par les utilisateurices comme AS (voir aussi la section 8.4.3.1 de notre RFC, sur l'authentfication des utilisateurices).
Le RFC rappelle que MLS ne met pas de contrainte à ces messages de changement du groupe. Si on veut le faire (par exemple créer des groupes fermés au public), cela doit être fait dans le protocole complet, qui inclut MLS pour la partie « chiffrement au groupe ». Par contre, MLS impose que tous les membres du groupe connaissent tous les autres membres. Il n'y a pas de possibilité d'avoir des membres cachés (cela serait difficilement compatible avec le chiffrement de bout en bout). Et le DS peut, selon les cas, être capable de trouver ou de déduire la composition d'un groupe (voir section 8.4.3.2).
Mais alors, que fait MLS ? Il gère la composition des groupes et ses changements dans le temps, et le matériel cryptographique associé. Via le DS, tous les membres du groupe génèrent les clés secrètes nécessaires et les messages peuvent être chiffrés pour tout le monde. MLS ne comprend pas le format des messages, il chiffre des octets, sans avoir besoin de connaitre l'application au-dessus.
Ah, et un peu de sécurité (section 8 du RFC). Il est très recommandé de faire tourner MLS sur un transport chiffré, comme QUIC (RFC 9000) ou TCP+TLS (RFC 8446) car, même si certains messages sont chiffrés, des métadonnées ne le sont pas. MLS fonctionne sur l'hypothèse que tout ce qui n'est pas une extrêmité du réseau (une des machines qui communiquent) est un ennemi (RFC 3552).
Autre question de sécurité, les push tokens, qui ont fait parler d'eux lors de discussions sur la sécurité de certaines messageries instantanées. Ils sont utilisés pour la distribution de contenu, par exemple pour prévenir les utilisateurices qu'un nouveau message est arrivé. Sans système de push, les machines clients devraient périodiquement interroger les serveurs, ce dont leurs batteries se plaindraient certainement. Mais les push tokens ont l'inconvénient de pouvoir être liés à des informations permettant d'identifier un·e utilisateurice. Cela ne compromet pas le contenu des messages (qui est chiffré) mais donne accès à des métadonnées bien révélatrices. Et les États utilisent cette possibilité. Le problème est compliqué car il n'y a pas de solution de remplacement, à part l'attente active. C'est ainsi que Proton a noté : « That said, we will continue to use Apple and Google push notifications when the services are available on the device because unfortunately they are favored heavily by the operating system in terms of performance and battery life. » Mais Tuta a fait un autre choix. Notre RFC suggère quelques pistes comme l'introduction de délais aléatoires.
La section 8 donne beaucoup d'autres conseils de sécurité et sa lecture est recommandée. Notez par exemple que le protocole MLS du RFC 9420 a fait l'objet de plusieurs analyses de sécurité (la liste figure dans la section 8.6).
Il existe un site Web du projet MLS mais il a très peu de contenu. Question mises en œuvre de MLS, une liste est disponible, citant, par exemple, la bibliothèque BouncyCastle ou bien OpenMLS (avec une documentation très complète).
L'article seul
Un million de routes
Première rédaction de cet article le 17 avril 2025
Si vous suivez l'actualité du routage sur l'Internet, vous avez peut-être vu des messages comme quoi on atteindrait bientôt « un million de routes ». Mais ça veut dire quoi et, surtout, est-ce que ce chiffre a un sens ?
Un exemple d'un tel message est ce
tweet. Le graphique qu'il référence indique qu'on est proche
de 999 000 routes. Si vous utilisez le service bgp.bortzmeyer.org,
vous verrez par contre qu'on a déjà dépassé le million (1 031 455
aujourd'hui). L'un des deux a-t-il tort ? Non.
Le fond de l'affaire est que le routage Internet est décentralisé. Revenons à comment ça fonctionne. Les routeurs du cœur de l'Internet (ce qui correspond à peu près à la zone sans route par défaut) annoncent à leurs pairs (en utilisant le protocole BGP) les préfixes d'adresses IP qu'ils savent joindre (un préfixe = une route). Ces pairs retransmettent ensuite à leurs propres pairs une partie des annonces reçues, selon leur politique. Parfois, ils agrègent plusieurs préfixes en un seul, plus général. Parfois, ils décident de ne pas transmettre des routes, par exemple parce qu'elles sont trop générales ou trop spécifiques. Résultat, chaque routeur voit une table de routage légèrement différente, plus ou moins grande.
Notez aussi que le chiffre cité dans le tweet plus haut est celui
pour IPv4. Il y a beaucoup plus de routes
IPv4 qu'IPv6 en raison du découpage de plus
en plus fin des préfixes, pour gérer la pénurie d'adresses
IPv4. IPv6, où l'agrégation est bien meilleure, a moins de préfixes
annoncés. Au passage, si vous êtes soucieux de l'empreinte
environnementale du numérique, notez qu'IPv6 impose donc une charge
moins forte aux routeurs, et devrait donc logiquement être déployé
partout. Un graphique
d'IPv4 : 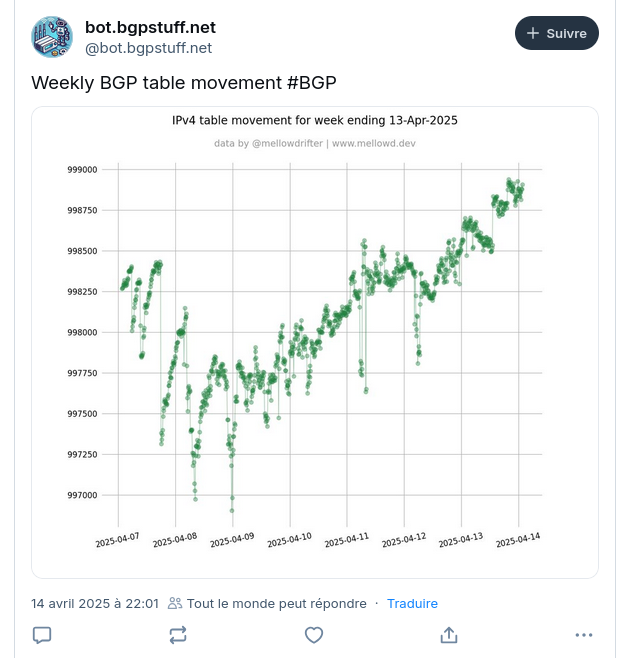
Le service bgp.bortzmeyer.org utilise le
RIS,
un système comprenant de nombreux routeurs, bien connectés. Il sert
pour l'étude et l'analyse. Il voit
donc davantage de routes qu'un routeur « de production ». (RouteViews a aujourd'hui
1 035 346 routes.) Mais même ces routeurs
« de production » ne voient pas tous la même chose, en fonction de
leurs pairs et de leur politique de filtrage. On ne pourra donc pas
faire un feu d'artifice pile au moment où l'Internet
IPv4 atteindra le million de routes.
L'article seul
RFC 9726: Operational Considerations for Use of DNS in Internet of Things (IoT) Devices
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : M. Richardson (Sandelman Software Works), W. Pan (Huawei Technologies)
Réalisé dans le cadre du groupe de travail IETF opsawg
Première rédaction de cet article le 1 avril 2025
Les objets connectés, vous le savez, sont une source d'ennuis et de risques de sécurité sans fin. Non seulement ils ne sont pas forcément utiles (faut-il vraiment connecter une brosse à dents au réseau ?) mais en outre, comme ils incluent un ordinateur complet, ils peuvent faire des choses auxquelles l'acheteur ne s'attend pas. Pour limiter un peu les risques, le RFC 8520 normalisait MUD (Manufacturer Usage Description), un mécanisme pour que le fournisseur du machin connecté documente sous un format analysable les accès au réseau dont l'objet avait besoin ce qui permet, par exemple, de configurer automatiquement un pare-feu, qui va s'assurer que la brosse à dents ne se connecte pas à Pornhub. Dans un fichier MUD, les services avec lesquels l'objet communique sont typiquement indiqués par un nom de domaine. Mais le DNS a quelques subtilités qui font que l'utilisation de ces noms nécessite quelques précautions, décrites dans ce nouveau RFC.
En fait, le RFC 8520 permet d'utiliser des noms ou bien des adresses IP, qui seront ensuite ajoutées dans les ACL du pare-feu. Évidemment, les noms de domaine, c'est mieux. Pas pour la raison qu'on trouve dans tous les articles des médias « les noms de domaine sont plus simples à retenir pour les humains » puisque les fichiers MUD ne sont pas prévus pour être traités par des humains. Mais parce qu'ils sont stables (contrairement aux adresses IP, qui changent quand on change d'hébergeur), qu'ils gèrent à la fois IPv4 et IPv6 et parce qu'ils permettent la répartition de charge, par exemple via un CDN.
Mais le pare-feu (sauf s'il espionne la résolution DNS préalable) ne voit pas les noms de domaine, il voit des paquets IP, avec des adresses IP source et destination. (Ainsi que les ports, si le paquet n'est pas chiffré.) Il va donc falloir résoudre les noms en adresses si on veut configurer le pare-feu à partir du fichier MUD, et c'est là que les ennuis commencent. Les exigences de sécurité sont contradictoires (section 9 du RFC) : on veut bloquer les accès au réseau mais « en même temps » les permettre. Cette permission est nécessaire pour que l'objet connecté puisse mettre à jour son logiciel, par exemple lorsqu'une faille de sécurité est découverte. Et c'est également nécessaire pour que le vendeur de l'objet puisse recevoir des quantités de données personnelles, qu'il revendra (ou se fera voler suite à un piratage).
Le plus simple (section 3 du RFC) pour traduire les noms de domaine du fichier MUD en adresses IP est évidemment que le contrôleur MUD, la machine qui lit les fichiers MUD et les traduit en instructions pour le pare-feu (RFC 8520, sections 1.3 et 1.6) fasse une résolution DNS normale et utilise le résultat. C'est simple et direct. Mais notre section 3 décrit aussi pourquoi ça risque de ne pas donner le résultat attendu. Par exemple, le résolveur DNS peut renvoyer les résultats (les différentes adresses IP) dans un ordre variable, voire aléatoire, comme décrit dans le RFC 1794. C'est souvent utilisé pour faire une forme grossière de répartition de charge. Si le résolveur renvoie toutes les adresses IP possibles, OK, le contrôleur MUD les autorise toutes dans le pare-feu. Mais s'il n'en renvoie qu'une partie, on est mal, celle(s) autorisée(s) ne sera pas forcément celle(s) utilisée(s) par l'objet connecté. Et la résolution peut dépendre du client (le RFC parle de « non-déterminisme » ; en fait, c'est parfaitement déterministe mais ça dépend du client, par exemple de sa géolocalisation). Si le serveur faisant autorité renvoie une seule adresse qui dépend de la localisation physique supposée de son client, et que le machin connecté et le contrôleur MUD n'utilisent pas le même résolveur DNS, des ennuis sont à prévoir : l'adresse autorisée sur le pare-feu ne sera pas celle réellement utilisée.
Si contrôleur et truc connecté utilisent le même résolveur, le risque d'incohérence est plus faible. Les réponses seront les mêmes pour les deux (contrôleur et chose connectée). Cela peut être le cas dans un environnement résidentiel où tout le monde passe par le CPE (la box) qui fait à la fois résolveur DNS, routeur NAT et pare-feu. Mais que faire si, par exemple, la brosse à dents ou l'aspirateur connecté utilisent un résolveur DNS public, quelque part dans le mythique nuage ?
La section 4 du RFC liste tout ce qu'il ne faudrait pas faire en matière d'utilisation du DNS par les objets connectés. Typiquement, l'objet connecté utilise HTTPS pour se connecter à son maitre (le vendeur de l'objet ; le gogo qui a acheté l'objet connecté croit en être propriétaire mais il dépend du vendeur, qui peut arrêter le service à tout moment). Pour le cas d'une mise à jour logicielle, le maitre informe alors si une mise à jour du logiciel est nécessaire, en indiquant l'URL où l'objet va pouvoir récupérer cette mise à jour. Évidemment, il est préférable pour la sécurité que cette mise à jour soit signée (RFC 9019). Notez que ce qui est bon pour la sécurité face au risque de piratage par un tiers n'est pas forcément bon pour le consommateur : la vérification de la signature va empêcher les utilisateurs de mettre leur propre logiciel par exemple parce que le vendeur ne fournit plus de mise à jour.
Questions bonnes pratiques, d'abord, il faut utiliser le DNS, donc un nom de domaine dans l'URL, pas des adresses IP littérales. Cette approche aurait certes l'avantage de fonctionner même quand la résolution DNS est défaillante, mais elle souffre des problèmes suivants :
- Il faut choisir entre une adresse IPv4 et IPv6, alors que le maitre ne sait pas forcément de quelle connectivité dispose l'objet. Si l'objet se connecte en IPv4 au maitre, celui-ci pourrait croire qu'une adresse IPv4 littérale est acceptable ce qui n'est pas vrai si l'objet est connecté via NAT64 (RFC 6146). Dans cet exemple, le DNS marcherait (RFC 6147) mais pas l'adresse littérale.
- Ensuite, l'adresse IP peut changer fréquemment, par exemple si le vendeur change d'hébergeur. C'est justement le principal avantage du DNS que de permettre une stabilité des identificateurs sur le long terme et non pas, comme on le lit souvent parce que « les noms sont plus lisibles et plus mémorisables que les adresses », argument qui ne s'applique pas aux objets connectés.
- Enfin, si la mise à jour est récupérée via HTTPS, ce qui est évidemment recommandé, le serveur doit obtenir un certificat et peu d'AC acceptent d'émettre des certificats pour des adresses IP (à l'heure de la publication de ce RFC, Let's Encrypt a annoncé qu'ils allaient le permettre mais cela ne semble pas encore fait).
Autre problème, des noms de domaine qui, en raison des systèmes utilisés sur le service HTTP, par exemple un CDN, changent souvent et de manière qui semble non déterministe. Modifier les fichiers MUD ne sera alors pas possible. Le RFC recommande, s'il faut absolument changer les noms souvent, de mettre un alias dans le fichier MUD, modifié à chaque fois que le nom change.
Toujours du côté des CDN, même s'ils ne sont pas les seuls à poser ce genre de problème, les noms trop génériques. Si tous les clients du service d'hébergement sont derrière le même nom de domaine, celui-ci sera difficile à modifier, et les effets d'une compromission pourront être plus étendus que souhaitable. Il vaut mieux des noms spécifiques à chaque client.
Les requêtes faites par le contrôleur MUD peuvent poser des problèmes de confidentialité (section 5 du RFC). Si le résolveur local n'est pas jugé digne de confiance, et que le contrôleur MUD utilise un résolveur distant, par exemple un résolveur public comme ceux de Cloudflare ou Quad9 (de préférence avec chiffrement, via DoH RFC 8484, DoT RFC 7858 ou DoQ RFC 9250), il faut s'assurer que l'objet va utiliser ce même résolveur (il n'y a pas aujourd'hui de mécanisme dans MUD pour faire cela automatiquement).
Les recommandations positives, maintenant (section 6). Le fichier MUD peut être obtenu de diverses façons (par exemple via un code QR comme documenté dans le RFC 9238), c'est son contenu qui compte. Les conseils de la section 6 sont en général du simple bon sens, qui correspondent aux bonnes pratiques habituelles d'utilisation des URL, mais qui ne sont pas toujours appliquées par les objets connectés. Notre RFC recommande :
- D'utiliser le DNS (et pas des adresses IP littérales comme le font trop de vendeurs),
- d'utiliser des noms contrôlés par le vendeur de l'objet (et pas par son hébergeur Web), éventuellement en utilisant des alias (RFC 9499, section 2),
- d'utiliser des CDN dont les serveurs faisant autorité retournent plusieurs réponses, quitte à les réordonnancer pour la répartition de charge, pour augmenter la probabilité que le contrôleur MUD et l'objet aient des adresses en commun,
- de ne pas utiliser des réponses adaptées au client DNS ; un mécanisme comme ECS (RFC 7871) permet de donner des réponses différentes selon l'adresse IP du client final (et pas celle du client que voit le serveur faisant autorité), ce qui va créer des problèmes si le contrôleur MUD et l'objet passent par des connexions Internet différentes,
- d'utiliser le résolveur local (celui indiqué via DHCP ou RA - RFC 8106), en s'appuyant sur les techniques décrites dans les RFC 9462 et RFC 9463 ; l'utilisation de résolveurs DNS publics est découragée, à mon avis pour de mauvaises raisons.
Notez que l'objet peut aussi utiliser des noms mais ne pas se servir du DNS pour les traduire en adresses IP. C'est le cas par exemple s'il utilise mDNS (RFC 6762 et RFC 8882) qui, en dépit de son nom, n'est pas du DNS, ce qui peut également poser des problèmes d'incohérence (l'objet n'obtenant pas la même adresse IP que le contrôleur MUD).
La section 8 revient sur les questions de vie privée (RFC 7626). Elle dit (ce qui est peut-être contestable) que les requêtes DNS d'un four à micro-ondes ne sont pas forcément un enjeu d'intimité mais que celles d'un sextoy le sont davantage. L'utilisation de DoT ou DoH va supprimer le risque d'une écoute par un tiers mais le résolveur, dans tous les cas, voit la requête et il faut donc choisir un résolveur de confiance, sauf à utiliser des techniques qui sont pour l'instant très rares, comme celle du RFC 9230. Ah, et le RFC discute aussi des risques posés par la divulgation de la version de logiciel actuellement utilisée par l'objet (qui va lui servir à savoir s'il faut une mise à jour) mais le RFC 9019 a déjà traité cela.
L'article seul
Association entre adresse IP et AS
Première rédaction de cet article le 29 mars 2025
Dans les discussions au sujet du réseau Internet, on voit souvent passer des demandes sur l'AS associé à une adresse IP ou bien le contraire. Mais les questions simples du genre « de quel AS dépend une adresse IP ? » sont… trop simples.
Il n'y a en effet pas d'association simple : une adresse IP peut être annoncée via BGP par plusieurs AS (même si ce n'est pas le cas le plus courant) et, surtout, surtout, il faut différencier l'association administrative (quel opérateur s'est fait allouer quelle adresse IP) et l'association technique (que voit-on avec BGP).
Commençons par la partie administrative. Un opérateur réseau est
typiquement LIR, membre d'un RIR, un registre d'adresses IP, dont
il obtient des adresses IP (ou plus exactement des préfixes
regroupant de nombreuses adresses). On peut obtenir l'information
sur ces allocations de préfixe avec des protocoles comme
whois ou RDAP (comme
pour les noms de domaine) ou simplement via le site Web du
registre. whois est très ancien, a plusieurs limites sérieuses (pas
de jeu de caractères normalisé, zéro
sécurité, il n'est même pas chiffré, etc). RDAP convient
mieux pour programmer. Ici, comme je suis vieux et
conservateur, je vais utiliser whois, d'autant plus que, dans
certains RIR, de l'information sur l'AS d'origine est distribuée en
whois mais pas en RDAP (qui n'a pas de réponse normalisée pour cette
information). Je me demande quel opérateur a
obtenu l'adresse 18.220.219.93 (choisie car
elle héberge un ramasseur d'une boite d'IA, qui vient de passer
sur ce blog).
% whois 18.220.219.93 … NetRange: 18.32.0.0 - 18.255.255.255 CIDR: 18.128.0.0/9, 18.64.0.0/10, 18.32.0.0/11 Organization: Amazon Technologies Inc. (AT-88-Z) …
OK, c'est une machine d'AWS. Je connais donc l'opérateur. La base de l'ARIN ne stockait apparemment pas le numéro d'AS de AWS. Celle du RIPE-NCC est en général de meilleure qualité donc on va réessayer avec une adresse européenne (un autre visiteur de ce blog, un ramasseur pour un moteur de recherche).
% whois 91.242.162.6 … inetnum: 91.242.162.0 - 91.242.162.255 netname: QWANT-NET org-name: QWANT SAS … route: 91.242.162.0/24 descr: QWANT SAS origin: AS199064
Cette fois, dans l'objet de type route (qui,
comme indiqué plus haut, n'est pas encore disponible pour RDAP), on a le
numéro de l'AS
associé à cette adresse. On peut obtenir des informations sur cet AS
via whois (whois AS199064…), RDAP, etc. Cette
information peut être utilisée pour bâtir automatiquement des règles
de filtrage pour les routeurs BGP (on utilise alors la base du RIR
comme IRR, Internet Routing
Registry) en considérant que seul cet AS peut annoncer ce
préfixe 91.242.162.0/24. Un exemple d'IRR
public, qui agrège les informations des RIR et en ajoute certaines,
est celui de
NTT. Rappelez-vous que toutes ces bases de données sont de
qualité… variable.
Mais tout ceci, c'est purement administratif. Ce sont des bases
de données relativement statiques qui sont stockées par les
RIR. Dans l'Internet vivant et dynamique, c'est autre chose. Là, il
faut regarder ce que contiennent les tables BGP, remplies par ce protocole de
routage. Là, ce sera bien plus dynamique (mais pas plus
« réel »). On peut consulter ces tables si on gère un routeur BGP
situé dans la DFZ
mais, comme ce n'est probablement pas le cas de la majorité des
lecteurices de ce blog, on va utiliser les
outils disponibles en ligne. Servons-nous par exemple du
service en bgp.bortzmeyer.org.
% curl -s https://bgp.bortzmeyer.org/18.220.219.93 18.220.0.0/14 16509
L'adresse IP allouée à Amazon est annoncée en
BGP par l'AS 16509. C'est l'AS d'Amazon, ce qui ne nous surprendra
pas mais, bien sûr, un préfixe peut être annoncé par un autre
opérateur que celui qui l'a réservé. Regardez par exemple
2001:678:4c::1, réservé par
l'Afnic, mais annoncé en BGP par son
hébergeur, PCH (dont le numéro d'AS, que je
vous laisse trouver, donne une bonne idée de la culture et de
l'ancienneté de cette organisation).
Ah, et j'avais dit qu'une adresse IP pouvait être annoncée par
plusieurs AS. C'est surtout le cas pour les services
anycastés. Regardez avec le
script bgproute (présenté dans la page citée plus haut).
% bgproute 2001:678:c::1 2001:678:c::/48 2486 2484 % bgproute 2001:503:d2d::30 2001:503:d2d::/48 36617 21313 40647 396599 397196 396566 396576 19836 397193 396555 396550
Le premier est annoncé par deux AS, le deuxième par pas moins de onze AS différents.
J'insiste sur le fait que les deux visions, l'administrative dans les bases des RIR, et la technique dans les tables BGP, sont aussi « authentiques » ou « correctes » l'une que l'autre. Ce sont simplement deux visions différentes de l'objet socio-technique assez complexe qu'est l'Internet.
L'article seul
DNS hackathon 2025 in Stockholm
First publication of this article on 23 March 2025
On 15 and 16 March 2025, I was at the DNS hackathon 2025 in Stockholm, organised by RIPE NCC, DNS-OARC and Netnod. I worked on a mechanism to synchronize the caches of DNS resolvers.
Hackathons are meant to be a collective work. After all, if you just code alone, you can as well stay at home/office. The organisers insist that you make big groups, with people of various profiles. (Speaking of diversity, there was apparently two women for more than thirty participants, which is typical for hackathons.) The subject I championed, implementation and interoperability of DELEG, did not raise sufficient interest so I went to another project, Poisonlicious. The idea for this project came from Quad9, a big public DNS resolver. Their network of resolvers is made of many sites, each with several physical machines, each physical machines hosting several virtual machines. When a DNS client asks the resolution of a domain name, each of the virtual machines has to do it on its own, without sharing work with the others, even if they were very close. The idea is therefore to synchronize the caches: when a machine finishes the resolution work, it sends a copy of the responses it got to other machines.
The practical work included:
- Patching the Unbound resolver to be able to both send and receive these data,
- Writing an Internet draft to document the idea, and the work to do (I worked mostly on this task).
In the current iteration of the Internet-Draft, the data is sent as an ordinary DNS message in UDP, authenticated by TSIG (otherwise, poisoning other machines with bad data is a risk). In the future, techniques like MQTT may be used for efficient synchronization.
The work done by Willem Toorop on Unbound is in this pull
request (it required to add TSIG support in Unbound, which
did not need it before). The Internet draft is draft-bortzmeyer-dnsop-poisonlicious. It
will be discussed in the dnsop IETF working
group. I also developed a small program in Python, using the excellent
dnspython library to
resolve a domain name and send it, following the protocol, to the
receiving machine: poisonlicious.pypoisonlicious.pcappython poisonlicious.py www.afnic.fr). But
nothing extraordinary, it is an ordinary DNS packet, with the TSIG
signature.
There were other interesting projects during this hackathon:
- resviz (DNS resolution visualizer). The goal is to be pedagogical (how resolvers work by showing the authoritative servers queried).
- Babies (from the Stork project, I let you find the reason for the name Babies). Monitoring / controlling multiple DNS servers from different vendors by proxying to their different APIs. NSD proved to be a bit tough during the hackathon. This project published its own report in a detailed article.
- LHB
("Lookup Hostname Best practices") addressed the problem with
getaddrinfo. Basically, the function
getaddrinfois available everywhere but very limited (no other types than the IP addresses, no information about whether the resolution was validated, for instance with DNSSEC, etc). Daniel Stenberg was not at the hackathon but was often quoted since he wrote a lot about getaddrinfo issues. Also, there was a great talk at the last FOSDEM on this: "getaddrinfo sucks, everything else is much worse". The hackathon project added some code in Ladybird. - Canned DNS was about breaking the DNS on purpose, in order to exercise testing tools like Zonemaster. They created a DNS server giving bad answers (two SOA, discrepancy between section count and the actual section, NXDOMAIN with data, etc). Unlike IBDNS, it will be specific to a test program. It is written in Go (not everyone subscribed yet to the Rust cult). I specially appreciated the fact that responses are not hardwired in the code but configured in TOML, which allows you to configure responses at will. Also, this project got the prize "most complete project".
- idIOT: DNS for Internet of stuff that spies on you. Current implementations of DNS on things are often broken. They do not respect TTL, they hardwired resolver IP addresses, etc. idIOT documented that. This hackathon project got the prize for "best project name".
- DohoT or Donion. An ordinary resolver knows both the IP address of its client and the question asked, which is bad for privacy. The idea is to add an intermediary (client → proxy → resolver, with encryption), the intermediary will know the client address but not the question and the resolver will only know the question. If they don't collude, it is safe. Tor is cool but too slow (long circuits, may be with high latency, which is really bad for the DNS). Oblivious DNS (RFC 9230) may be the solution but is a new protocol. Six solutions were tested during the hackathon, ordinary DoH is the fastest (of course), improved Tor with shorter directed circuits may be the best solution.
Thanks to Vesna Manojlović who convinced me to come, to Johanna Eriksson and Denesh Bhabuta for the organisation, and to my nice project group, Willem Toorop, Babak Farrokhi and Moin Rahman.
L'article seul
RFC 9724: Randomized and Changing MAC Address State of Affairs
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : JC. Zúñiga (CISCO), CJ. Bernardos (UC3M), A. Andersdotter (Safespring AB)
Pour information
Réalisé dans le cadre du groupe de travail IETF madinas
Première rédaction de cet article le 20 mars 2025
Dans le contexte de la surveillance massive qui s'exerce contre les utilisateurices de l'Internet, tout identifiant un peu stable peut être utilisé pour pister quelqu'un. On en laisse, des traces ! C'est par exemple le cas avec l'adresse MAC. Ce nouveau RFC décrit les mécanismes existants pour diminuer le risque de pistage par l'adresse MAC. Il ne spécifie pas un protocole, il liste les solutions.
Ne croyez donc pas les médias et les politiciens qui vous diraient que le problème de l'Internet, c'est l'anonymat. C'est tout le contraire : il est extrêmement difficile d'utiliser l'Internet sans laisser de traces partout, traces qui peuvent être corrélées si on réutilise un identifiant, comme l'adresse MAC (dite également adresse Ethernet ou bien adresse physique).
(Au passage, le RFC contient une remarque très désagréable comme quoi l'une des causes des problèmes de vie privée serait « le manque d'éducation [des utilisateurices ?] ». S'il est vrai que la littératie numérique en matière de sécurité est très perfectible, il ne faudrait pas pour autant tout rapporter à l'ignorance. Les utilisateurices ne sont pas responsables de la surveillance massive, dont l'ubiquité et la sophistication font qu'il est difficile de se défendre, même pour un·e expert·e. Et les innombrables entreprises et États qui pistent les utilisateurices ne le font pas par ignorance mais cherchent en toute conscience à récolter le maximum de données.)
Le problème du pistage se place à tous les niveaux du modèle en couches ; les adresses MAC en couche 2, les adresses IP en couche 3, les cookies pour le Web en couche 7, etc. Pour la couche 2, sujet de notre RFC, voyez par exemple l'analyse « Wi-Fi internet connectivity and privacy: Hiding your tracks on the wireless Internet » (comme l'IEEE fait partie de ces organisations de normalisation réactionnaires qui ne permettent pas l'accès libre à leurs documents, prenez une copie), ou bien cet article décrivant comment les poubelles vous pistent.
Le problème est d'autant plus sérieux qu'aujourd'hui, plein d'équipements électroniques ont la WiFi (en termes plus techniques, IEEE 802.11) et donc une adresse MAC unique, qui peut servir au pistage. On ne pense pas forcément à ces équipements comme étant des ordinateurs, susceptibles d'émettre et donc de révéler leur présence. Quiconque écoute le réseau va voir ces adresses, il n'y a pas besoin d'être actif, une écoute passive suffit. Même sans association avec la base, la machine se signale par les Probe Request qu'elle envoie. Dans le cas typique, l'adresse 802.11 est composée de deux parties, l'OUI (Organizationally Unique Identifier), qui identifie le fournisseur, et le Network Interface Controller Specific, qui identifie une des machines (en toute rigueur, plutôt une des interfaces réseau) dudit fournisseur. La combinaison des deux fait une adresse unique (au moins en théorie), traditionnellement attribuée à la fabrication et pas changée ensuite. Cette adresse unique est donc, malheureusement pour la vie privée, un bon identificateur stable. Mais une adresse MAC peut aussi être localement gérée (elle n'est alors plus forcément unique), et, contrairement à ce que croient certaines personnes, l'adresse globale par défaut n'est pas obligatoire. (Un bit dans l'adresse indique si elle est globale ou locale. Le RFC 8948 définit même un plan d'adressage pour ces adresses locales.) On peut donc échapper au pistage en changeant d'adresse de temps en temps (cf. l'article de Gruteser et D. Grunwald, « Enhancing location privacy in wireless LAN through disposable interface identifiers: a quantitative analysis »). Ces questions de vie privée liées à l'adresse MAC sont décrites plus en détail dans l'article « Privacy at the Link Layer », de Piers O'Hanlon, Joss Wright et Ian Brown, présenté à l'atelier STRINT, dont le compte-rendu a été le RFC 7687. Notre RFC rappelle aussi que, bien sûr, la protection de la vie privée ne dépend pas uniquement de cette histoire d'adresse MAC et que les surveillants ont d'autres moyens de pistage, qu'il faut combattre également, cf. section 9.
Un peu d'histoire : l'IEEE, qui normalise 802.11 et donc les adresses MAC, avait pour la première fois traité le problème lors d'un tutoriel en 2014, qui avait suivi l'atelier STRINT (celui dont le compte-rendu est dans le RFC 7687). Suite à ce tutoriel, l'IEEE avait créé l'IEEE 802 EC Privacy Recommendation Study Group, ce qui avait finalement donné naissance à des documents IEEE comme IEEE 802E-2020 - IEEE Recommended Practice for Privacy Considerations for IEEE 802 Technologies et 802c-2017 - IEEE Standard for Local and Metropolitan Area Networks:Overview and Architecture--Amendment 2: Local Medium Access Control (MAC) Address Usage. Les idées documentées avaient été testées lors de réunions plénières de l'IEEE et de l'IETF. Ces tests ont montré que les collisions (deux adresses MAC identiques) étaient extrêmement rares. Elles ont aussi permis de constater que certains identificateurs visibles (comme celui envoyé en DHCP, cf. RFC 7819) restent stables et qu'il ne suffit donc pas de changer l'adresse MAC. Je recommande la lecture du rapport « IEEE 802E Privacy Recommendations & Wi-Fi Privacy Experiment @ IEEE 802 & IETF Networks> », présenté à l'IETF 96 à Berlin en 2016.
Depuis, l'aléatoirisation des adresses MAC a été largement déployée, sur iOS, sur Android, sur Microsoft Windows, sur Fedora, etc. Il n'y a évidemment pas de solution parfaite et des chercheurs ont déjà trouvé comment contourner l'aléatoirisation. Cela a mené à une nouvelle norme IEEE, 802.11aq.
Ce changement de l'adresse MAC a ensuite posé problème à certains opérateurs de réseaux mobiles. (Voir aussi « IEEE 802.11 Randomized And Changing MAC Addresses Topic Interest Group Report » et « RCM A PAR Proposal ».)
La question de la vie privée s'est beaucoup posée à l'IETF dans le contexte de l'auto-affectation des adresses IPv6 (SLAAC : Stateless Address Autoconfiguration). Le RFC 1971 et ses successeurs (le dernier en date est le RFC 4862) prévoyaient que la partie spécifique à la machine de l'adresse IPv6 soit fondée sur l'adresse MAC, ce qui permettait le pistage. Cette méthode, qui a fait couler beaucoup d'encre, est désormais déconseillée (RFC 8064). La méthode recommandée maintenant est celle du RFC 8981, avec ses adresses aléatoires et temporaires. (Elles ont d'autres avantages, comme de limiter la durée pendant laquelle on peut se connecter à une machine depuis l'extérieur.) Évidemment, ces adresses temporaires ne conviennent pas aux serveurs (qui doivent être joignables) ni aux cas où l'administrateur réseau veut pouvoir garder trace des adresses IP des machines (dans ce dernier cas, le RFC 7217, avec ses adresses stables tant qu'on reste dans le même réseau, est la solution recommandée).
On l'a dit, l'adresse MAC n'est pas le seul moyen qu'on a de suivre une machine à la trace. Les identifiants qui figurent dans la requête DHCP en sont un autre. Le RFC 7844 rassemble les recommandations faites aux auteur·es de logiciels DHCP pour limiter ce pistage.
On a donc vu qu'on pouvait changer son adresse MAC et que c'était une bonne chose pour la protection de sa vie privée. Mais la changer pour quoi ? La section 6 de notre RFC résume toutes les politiques possibles :
- Adresse MAC fixe déterminée par le fournisseur (c'est la politique ancienne et traditionnelle) et enregistrée en dur dans l'interface réseau.
- Adresse permanente mais générée localement, sur la machine, typiquement au premier démarrage. On parle de PDGM (Per-Device Generated MAC).
- Adresse temporaire générée localement, au démarrage de la machine. On parle de PBGM (Per-Boot Generated MAC). Plus besoin de mémoire stable.
- Adresse fixe générée localement, pour chaque réseau. L'adresse est stockée dans une mémoire stable, indexée par un identificateur du réseau (le SSID pour le Wifi, et diverses heuristiques utilisant par exemple STP pour les réseaux fixes). Cette politique empêche le pistage trans-réseau mais permet une stabilité utile pour l'administrateur du réseau. On parle de PNGM (Per-Network Generated MAC).
- Adresse temporaire renouvelée régulièrement, par exemple toutes les douze heures. On parle de PPGM (Per-Period Generated MAC).
- Adresse temporaire par « session ». La session étant par exemple une connexion via le portail captif. On parle de PSGM (Per-Session Generated MAC).
Que font les systèmes d'exploitation
d'aujourd'hui ? La section 7 détaille les pratiques actuelles. Un
point important est que, depuis longtemps, tous ces systèmes mettent
en œuvre une forme ou l'autre d'aléatoirisation, pour les questions
de vie privée citées ici. Comme la situation évolue, plutôt que de
lire cette section du RFC, vous avez peut-être intérêt à suivre
en ligne. Au moment de la rédaction de cet article, les
versions actuelles d'Android et
d'iOS étaient en PNGM (adresse choisie
aléatoirement mais liée au SSID). Idem pour
Debian et
Windows. Mais lisez les détails, qui peuvent
dépendre de points subtils. 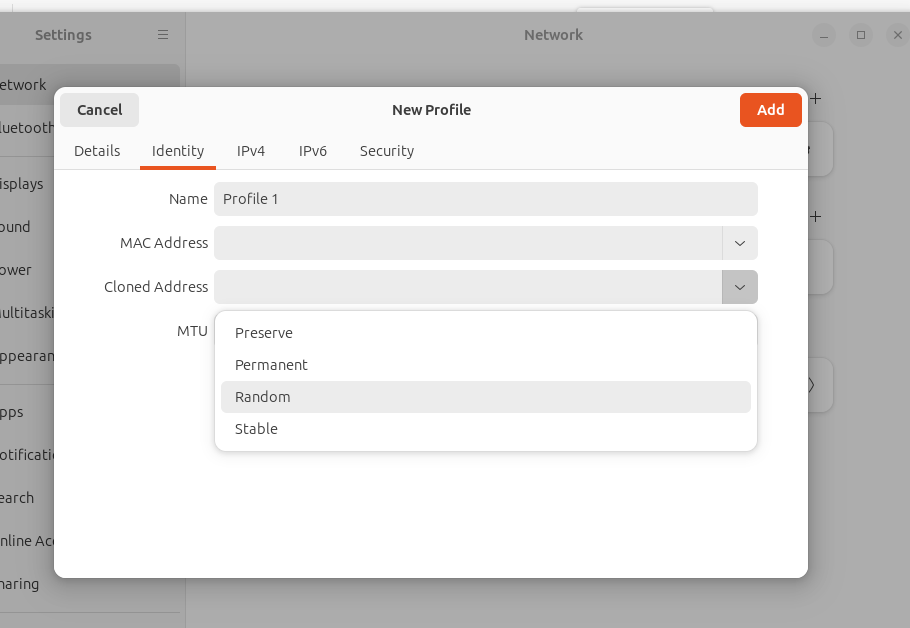
L'article seul
RFC 9694: Guidelines for the Definition of New Top-Level Media Types
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : M.J. Dürst (Aoyama Gakuin University)
Réalisé dans le cadre du groupe de travail IETF mediaman
Première rédaction de cet article le 19 mars 2025
Vous savez que les types de médias
comportent un type de premier niveau et un sous-type. Dans
image/gif, image est le
type de premier niveau et gif le sous-type. On
crée des sous-types tout le temps mais les types, l'identificateur
qui est au premier niveau, c'est bien plus rare. La création du type
haptics
(données haptiques), qui a été faite dans le RFC 9695, a été l'occasion de formaliser un
peu plus le processus de création de types de médias.
Vous voulez créer un nouveau type de
médias (également appelé type MIME) ? Les
types existants comme text,
image et application ne
vous suffisent pas ? Alors, il vaut mieux lire ce RFC 9694, qui explique les principes. Le RFC 6838, qui spécifie les types de médias est assez vague sur
la création de nouveaux types de premier niveau (cf. sa section
4.2.7), sans doute parce qu'on ne comptait pas en voir arriver
beaucoup. Notre RFC 9694 comble ce manque, devenu
évident avec la création du type haptics
dans le RFC 9695.
Attention, ne pas confondre les types de médias de premier niveau
avec les arbres qui permettent d'étiqueter les sous-types, comme
vnd (abréviation de vendor),
pour les sous-types spécifiques à un fournisseur, comme
application/vnd.adobe.flash.movie pour
un format qu'on ne regrettera
pas.
Donc, contrairement aux sous-types, qui apparaissent tout le
temps et ne font pas forcément l'objet d'un RFC, la création de types est plus
rare. Le dernier créé, avant haptics/, était
font/, par le RFC 8081. L'une des raisons de la séparation type/sous-type
est que, dans certains cas, le type peut indiquer, au logiciel qui
lit un fichier, une application générique (si on tombe sur un
image/sous-type-inconnu, lancer un logiciel de
visualisation d'imges qui gère beaucoup de formats est une solution
raisonnable ; si on tombe sur un
text/sous-type-inconnu, on sait qu'un humain
pourra à peu près le lire avec un éditeur générique). Le RFC note
qu'autrefois il était même prévu que cet aiguillage puisse se faire
vers différents matériels (envoyer
image/nimporte-quoi à l'imprimante,
video/nimporte-quoi à la télé) mais
qu'aujourd'hui, où les machines sont bien plus généralistes, cela
n'a plus trop de sens.
Donc, si vous voulez enregistrer un nouveau type de médias de premier niveau, la section 2 de notre RFC liste les critères obligatoires d'évaluation :
- Le type doit être décrit dans un RFC qui est sur le chemin des normes (Standards Track, cf. la politique « Action de normalisation », RFC 8126, section 4.9) donc approuvé par l'IETF.
- La spécification doit citer, dans sa section IANA considerations l'ajout au registre des types de premier niveau,
- Elle doit bien indiquer les critères d'évaluation pour les sous-types (qu'est-ce qui est acceptable et qu'est-ce qui ne l'est pas).
- Il faut qu'au moins un sous-type soit décrit, pour bien
montrer qu'il y a un usage réel, pas juste
théorique. (
haptics/a commencé avec trois sous-types.)
Moins cruciaux sont d'autres critères, comme :
- Si le type est déjà utilisé informellement, c'est un bon signe de son utilité.
- Mais en même temps, le RFC déconseille d'utiliser des types non enregistrés, ce qui est contradictoire avec le critère précédent.
- Il n'est pas nécessaire de créer un groupe de travail
IETF
dédié mais ça arrive parfois.
model/a été créé par le RFC 2077 sans groupe de travail,font/(RFC 8081) a été l'œuvre d'un groupe de travail dédié,haptics/(RFC 9695) a été fait par un groupe de travail qui avait également d'autres sujets.
Il y a aussi des anti-critères.
- Un type de premier niveau ne doit pas être juste un pointeur
vers un autre registre (le RFC cite le cas fictif d'un type
oid/qui pointerait vers des object identifiers). - Les types de médias sont prévus pour aider les applications qui lisent des ressources Internet à les faire traiter par le logiciel approprié. Ce ne sont pas un mécanisme de typage générique, on ne va pas faire une ontologie avec.
- Un éventuel nouveau type ne doit pas marcher sur les
plate-bandes d'un type existant. On ne pourrait sans doute pas
créer un
code/pour le code source puisqu'il existe déjàtext/(même si peu de langages de programmation ont eu un sous-type enregistré, le RFC 9239 est plutôt une exception). - Et pas question de commencer un nom de type par
x-, le RFC 6648 explique pourquoi.
La section 3 du RFC est pour les féru·es d'histoire. Elle
documente l'évolution de ces types de médias. Leur apparition date du
RFC 1341 en 1992, qui
créait les « classiques » text/,
image/, audio/… Le premier
type de premier niveau créé par la suite a été
matter-transport/ (pour indiquer que le message
contient de la matière, pas juste de l'information) en
1993 dans le RFC 1437
(mais regardez la date du RFC avant de critiquer). Le premier
« sérieux » type de premier niveau en dehors des « classiques »,
model/, n'a été créé qu'en
1997 par le RFC 2077. example/ date de
2006 (RFC 4735) et
font/ de 2017 (RFC 8081). Enfin, le dernier,
haptics/, date de cette
année, avec le RFC 9695.
Il existe aussi des types utilisés mais pas enregistrés. Wikipédia parle d'un type chemical/, décrit dans un article mais jamais passé par le mécanisme d'enregistrement que décrit notre RFC, et donc absent du registre.
La section 4 de notre RFC synthétise les règles et procédures pour l'enregistrement d'un nouveau type (rappel : politique « Action de normalisation », RFC 8126) et crée formellement le registre des types de premier niveau.
Si vous voulez créer un nouveau type de médias de premier niveau,
je signale que scent/
(pour distribuer des odeurs sur l'Internet) n'a pas été
enregistré. Il faut dire qu'à ma connaissance, il n'existe pas de
format pour les odeurs, qui permettrait d'avoir le premier
sous-type. Et ce manque de format vient probablement du fait qu'on
n'a pas de synthétiseur d'odeurs qui serait capable de rendre le
contenu du fichier de manière perceptible par notre odorat. (Trois
autres sens sont couverts par image/,
audio/
et haptics/
mais on n'a rien non plus pour le
goût.)
_L%27Odorat_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
_Le_Vue_(La_Dame_%C3%A0_la_licorne)_-_La_Dame_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
_L%27Ou%C3%AFe_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
_Le_toucher_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris_-_Le_toucher.jpg){kind=link}
_Le_Go%C3%BBt_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
L'article seul
RFC 9695: The 'haptics' Top-level Media Type
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : Y. K. Muthusamy, C. Ullrich
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF mediaman
Première rédaction de cet article le 19 mars 2025
L'enregistrement d'un nouveau type de
média de premier niveau est plutôt rare (le dernier
avait été font/ en 2017). Notre
RFC introduit le type
haptics/, pour les formats de fichier des
interfaces haptiques, celles qu'on touche et
qui vous touchent (une manette de jeu vidéo à retour
d'effort, par exemple).
De telles interfaces se trouvent dans de nombreux secteurs, le jeu vidéo, bien sûr, mais aussi la simulation (simulateurs de vol, par exemple), la robotique, des trucs pour adultes, etc. Contrairement à l'audio et à la vidéo, qui s'affichent directement, l'haptique est une réaction à votre toucher. (Enfin, c'est ce que dit le RFC mais les fauteuils de cinéma haut de gamme qui vous secouent pendant les scènes d'action sont aussi de l'haptique.) Les interfaces haptiques peuvent être mises en œuvre de diverses façons, par exemple des petits moteurs ou des matériaux piézoélectriques.
Il existe divers formats pour représenter des actions haptiques
et il est donc nécessaire de les étiqueter proprement pour quand les
fichiers voyagent sur l'Internet. Le mécanisme des types
de médias est décrit dans le RFC 6838. Il est complété par le RFC 9694 pour la création de nouveaux types de premier niveau,
comme haptics/, créé
par notre RFC.
On trouve des dispositifs haptiques dans un certain nombre de machines (PlayStation, Switch, etc) et le W3C a une norme pour les vibrations (et même deux).
À noter que les données haptiques peuvent être combinées avec des
données audio et vidéo, par exemple pour une simulation plus
réussie. La norme ISOBMFF (ISO 14496) est
un exemple mais on trouve aussi des instructions haptiques
transportées, par exemple, dans RTP. Je n'ai pas 216 francs suisses pour
vérifier mais le RFC dit que la première mention d'un type de médias
haptics/ vient de cette norme ISO. On pourra
donc avoir, par exemple, dans le futur,
haptics/mp4.
haptics/ ne concerne pas que le toucher au
sens strict. Outre les effects tactiles, il y a aussi la
kinésthésique (des forces plus importantes),
la friction, l'utilisation de sons qu'on n'entend pas (par exemple
ultrasons) mais qui ont quand même un effet
sur le corps et même la température. Vous voyez que cela ne pouvait
pas rentrer dans audio/ ou
video/.
Il existe déjà plusieurs formats pour les données haptiques :
- IVS que l'on trouve chez certains fournisseurs d'ordiphones,
- hjif (norme ISO 23090),
- hmpg (norme ISO 23090),
- AHAP, d'origine Apple,
- Une extension d'origine Google à Ogg,
- HAPT, qui semble surtout utilisé au Japon,
- IEEE 1918 (126 dollars étatsuniens, l'IEEE est moins chère que l'ISO) ,
- Et j'en oublie…
Les trois premiers ont déjà été mis dans le
registre : haptics/ivs,
haptics/hjif
et haptics/hmpg.
Le type application/ aurait pu convenir mais
haptics/ est plus spécifique et, surtout, ce
sont des données, pas du code. En parlant de cela, la section 3 du
RFC détaille quelques points de sécurité. Outre les problèmes
classiques d'analyser des données venues de l'extérieur (les formats
complexes mènent souvent à des failles de sécurité dans
l'analyseur), les actuateurs peuvent être
dangereux (un actuateur thermique qui brûle, un actuateur à retour
de force qui brutalise) et il ne faut donc pas exécuter aveuglément
toutes les instructions que contient un fichier de type
haptics/.
L'article seul
RFC 9755: IMAP Support for UTF-8
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : P. Resnick (Episteme Technology
Consulting), J. Yao
(CNNIC), A. Gulbrandsen (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF extra
Première rédaction de cet article le 18 mars 2025
Successeur du RFC 6855, voici la normalisation de la gestion d'Unicode par le protocole IMAP (dans sa version 4rev1) d'accès aux boîtes aux lettres.
Normalisé dans le RFC 3501, IMAP version 4rev1 permet d'accéder à des boîtes aux lettres situées sur un serveur distant. Ces boîtes peuvent avoir des noms en Unicode, les utilisateurs peuvent utiliser Unicode pour se nommer et les adresses gérées peuvent être en Unicode. L'encodage utilisé est UTF-8 (RFC 3629). C'est donc une des composantes d'un courrier électronique complètement international (RFC 6530). (Il existe un RFC équivalent pour POP le RFC 6856. Pour IMAP 4rev2, normalisé dans le RFC 9051, UTF-8 est prévu dès le début.)
Tout commence par la possibilité d'indiquer le support
d'UTF-8. Un serveur IMAP, à l'ouverture de la connexion, indique les
extensions d'IMAP qu'il gère et notre RFC normalise
UTF8=ACCEPT (section 3). En l'utilisant, le
serveur proclame qu'il sait faire de l'UTF-8. Par le biais de
l'extension ENABLE (RFC 5161), le
client peut à son tour indiquer qu'il va utiliser UTF-8. Une fois
que cela sera fait, client et serveur pourront faire de l'IMAP
UTF-8. Cette section 3 détaille la représentation des chaînes de
caractères UTF-8 sur le réseau.
Les nouvelles capacités sont toutes décrites dans la section 10 et enregistrées dans le registre IANA.
On peut donc avoir des boîtes aux lettres qui ne peuvent être manipulées qu'en UTF-8. Les noms de ces boîtes doivent se limiter au profil « Net-Unicode » décrit dans le RFC 5198, avec une restriction supplémentaire : pas de caractères de contrôle.
Il n'y a bien sûr pas que les boîtes, il y a aussi les noms
d'utilisateurs qui peuvent être en Unicode, et la section 5 spécifie
ce point. Elle note que le serveur IMAP s'appuie souvent sur un
système d'authentification externe (comme
/etc/passwd sur Unix) et
que, de toute façon, ce système n'est pas forcément UTF-8. Prudence,
donc.
Aujourd'hui, encore rares sont les serveurs IMAP qui gèrent
l'UTF-8. Mais, dans le futur, on peut espérer que
l'internationalisation devienne la norme et la limitation à US-ASCII
l'exception. Pour cet avenir radieux, la section 7 du RFC prévoit
une capacité UTF8=ONLY. Si le serveur
l'annonce, cela indique qu'il ne gère plus l'ASCII seul, que tout
est forcément en UTF-8.
Outre les noms des boîtes et ceux des utilisateurs, cette norme IMAP UTF-8 permet à un serveur de stocker et de distribuer des messages dont les en-têtes sont en UTF-8, comme le prévoit le RFC 6532.
La section 8 expose le problème général des clients IMAP
très anciens. Un serveur peut savoir si le client accepte UTF-8 ou
pas (par le biais de l'extension ENABLE) mais,
si le client ne l'accepte pas, que peut faire le serveur ? Le
courrier électronique étant asynchrone, l'expéditeur ne savait pas,
au moment de l'envoi si tous les composants, côté réception, étaient
bien UTF-8. Le RFC n'impose pas une solution unique. Le serveur peut
dissimuler le message problématique au client archaïque. Il peut
générer un message d'erreur. Ou il peut créer un substitut, un
ersatz du message originel, en utilisant les
algorithmes du RFC 6857 ou du RFC 6858. Ce ne sera pas parfait, loin de là. Par exemple, de
tels messages « de repli » auront certainement des
signatures invalides. Et, s'ils sont lus par
des logiciels différents (ce qui est un des avantages d'IMAP),
certains gérant l'Unicode et d'autres pas, l'utilisateur sera
probablement très surpris de ne pas voir le même message, par
exemple entre son client traditionnel et depuis son
webmail. C'est affreux, mais inévitable :
bien des solutions ont été proposées, discutées et même décrites
dans des RFC (RFC 5504) mais aucune d'idéale
n'a été trouvée.
Je n'ai pas testé les implémentations en logiciel libre mais, apparemment, la bibliothèque standard de Python est déjà conforme à ce RFC (cherchez "UTF" dans la documentation), ainsi que celle de Java. Si vous connaissez des utilisateurices du courrier électronique en Unicode, demandez leur quel serveur IMAP ielles utilisent.
Le résumé des différences (peu importantes) avec son
prédécesseur, le RFC 6855 est dans l'annexe
B. UTF8=APPEND disparait, et FETCH
BODYSTRUCTURE voit sa sémantique modifiée.
L'article seul
RFC 9745: The Deprecation HTTP Header Field
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : S. Dalal, E. Wilde
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpapi
Première rédaction de cet article le 17 mars 2025
Ce nouveau champ de l'en-tête HTTP sert à indiquer que la ressource demande va être (ou a été) abandonné et qu'il faut penser à migrer. Il sert surtout pour les API HTTP.
(Et si vous ne savez pas ce qu'est une ressource, dans le monde HTTP, voyez la section 3.1 du RFC 9110.)
L'idée de ce champ est de permettre aux clients HTTP d'être
informés, de préférence à l'avance, du fait qu'une ressource est
considérée comme abandonnée et qu'ils devraient donc aller voir
ailleurs. Par exemple, si on a une API avec une fonction d'URL
https://api.example.com/v1/dosomething et que
cette fonction est finalement jugée inutile, on pourra faire en
sorte que tout appel à cet URL renvoie un champ
Deprecation: dans l'en-tête, que les clients
HTTP comprendront. (Ce champ a été ajouté dans le registre
des champs de l'en-tête HTTP.)
Deprecation: est juste une information, la
ressource continue à fonctionner.
Un exemple est disponible sur ce blog (je n'en ai pas trouvé de « vraies »), qui a quelques API :
% curl -i https://www.bortzmeyer.org/apps/limit HTTP/1.1 200 OK Date: Sat, 22 Feb 2025 15:50:23 GMT Server: Apache/2.4.62 (Debian) Deprecation: @2147483648 Link: <https://www.bortzmeyer.org/9745.html>; rel="deprecation"; type="text/html" Content-Type: text/plain Will be deprecated on 2038-01-19T03:14:08Z.
Que veut dire « @2147483648 » ? Le champ
Deprecation: indique le nombre de secondes
depuis l'epoch
Unix. La commande GNU
date vous permet de voir facilement cet instant :
% date --date=@2147483648 mar. 19 janv. 2038 03:14:08 UTC
C'est, dans cet exemple, au moment de la bogue de
2038 que cette ressource ne sera plus maintenue. La
syntaxe utilisée est celle des objets de type Date des champs HTTP
structurés (RFC 9651, section
3.3.7). D'ailleurs, cette question de syntaxe avait fait l'objet
d'une intéressante
discussion à l'IETF, d'autres champs HTTP, comme
Sunset:, mentionné plus loin, utilisent une
autre syntaxe pour les dates. Et vous trouverez, par exemple sur
Stack Overflow, d'innombrables articles qui
utilisent pour le champ Deprecation:, la
syntaxe qui avait été initialement proposée (et qui était la même
que celle de Sunset:).
Cette indication d'un futur abandon ne s'applique qu'à la
ressource demandée. Si vous retirez un ensemble de ressources (par
exemple votre API avait plusieurs ressources commençant par
https://api.example.com/v1/ et désormais vous
êtes passé à une nouvelle version, avec le préfixe
https://api.example.com/v2/), vous devrez le
spécifier dans la documentation associée (continuez la lecture, on va
parler de cette documentation).
Vous avez sans doute remarqué dans l'exemple plus haut le champ
Link:. Il sert à donner des détails, sous forme
d'un URL où vous trouverez davantage d'informations. Au passage, le
moment indiqué dans le champ Deprecation: peut
être dans le passé indiquant que, quoi que la ressource fonctionne
encore, elle est déjà considérée comme abandonnée (et donc sans doute
plus maintenue). Les liens sont normalisés dans le RFC 8288 et le type de lien deprecation
est désormais dans le registre
des types de liens.
Arrivés à ce stade, si vous connaissez bien HTTP, vous vous
demandez sans doute « Et Sunset: (RFC 8594), alors, il
sert à quoi ? » Je dois dire qu'il n'est pas évident d'expliquer
pourquoi les deux existent, mais notez quand même que
Deprecation: est toujours
plus tôt que Sunset:, qui représente donc la
fin effective (Deprecation: pouvant être
simplement une reclassification de la ressource, sans qu'elle cesse
de fonctionner). Un exemple donné par le
RFC :
Deprecation: @1688169599 Sunset: Sun, 30 Jun 2024 23:59:59 UTC
Dans cet exemple, la ressource cesse d'être officiellement disponible le 1 juillet 2023 mais n'est réellement retirée que le 30 juin 2024. Après cette deuxième date, on peut supposer qu'à cet URL, on récupèrera un code de retour 404 ou, mieux, 410 (RFC 9110, section 15.5.11).
Quelques articles qui peuvent être utiles lors d'une stratégie de retrait d'une ressource :
- Je vous recommande la lecture de « API Lifecycle, Versioning, and Deprecation ». Notez que la solution qu'il propose pour indiquer le futur retrait d'une API n'utilisait pas encore la syntaxe de ce RFC, qui est venu après, mais les concepts sont les mêmes.
- « How to deprecate an entire API in OpenAPI? » sur Stack Overflow,
- « The right way to turn off your old APIs » (attention, il utilise l'ancienne syntaxe pour exprimer la date d'abandon).
Et le champ Expires: (RFC 9111, section 5.3) ? Rien à voir,
Expires: concerne le contenu, mais l'URL reste
stable et fonctionnel.
Un petit mot sur la sécurité (section 7 du RFC). Le champ
Deprecation: n'est qu'une indication et il ne
faut sans doute pas agir automatiquement sur la base de ce
champ. Toujours vérifier la documentation !
Pour traiter ce champ, ainsi que le Sunset: du
RFC 8594, regardez ce script Python. Quelques exemples
d'utilisation dans le monde :
- L'entreprise de mode Zalando a un guide de la conception d'API qui recommande ce champ.
- La mise en œuvre dans la bibliothèque Requests a été discutée mais le consensus a plutôt été que c'était à l'application utilisatrice de gérer cela.
- Mon client pour l'API RIPE Atlas, Blaeu, a ce code pour tester si l'API utilisée ne va pas être abandonnée, tiré de l'exemple Python cité plus haut.
- Et bien plus encore qui ont le concept mais avec une autre syntaxe, choisie avant ce RFC.
L'article seul
RFC 9743: Specifying New Congestion Control Algorithms
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : M. Duke (Google), G. Fairhurst (University of Aberdeen)
Réalisé dans le cadre du groupe de travail IETF ccwg
Première rédaction de cet article le 14 mars 2025
La lutte contre la congestion du réseau est une tâche permanente des algorithmes utilisés dans l'Internet. Si les émetteurs de données envoyaient des octets aussi vite qu'ils le pouvaient, sans jamais réfléchir, l'Internet s'écroulerait vite. Des protocoles comme TCP ou QUIC contiennent donc des algorithmes de contrôle de la congestion. Il y en a plusieurs, certains peuvent être néfastes, et ce RFC, qui remplace le RFC 5033, explique comment de nouveaux algorithmes doivent être évalués avant d'être déployés en vrai. Bref, la prudence est nécessaire.
Le RFC 2914 expose les principes généraux du contrôle de congestion du réseau. Notre RFC 9743 a un autre but : créer un cadre d'évaluation des algorithmes de contrôle de la congestion. Car c'est très difficile de concevoir et de spécifier un tel algorithme. Songez qu'il doit fonctionner sur des types de liens très différents, des réseaux à énorme capacité sur les courtes distance d'un centre de données (RFC 8257) à des liaisons radio à grande distance et avec un fort taux de perte de paquets. Il doit fonctionner en Wifi, sur la fibre, sur des liens surchargés, bien exploiter des liens à forte capacité, supporter des liens à forte latence, etc. Et l'efficacité de ces algorithmes dépend aussi de l'application qui va les utiliser, la vidéoconférence ne produisant pas les mêmes effets que le transfert de fichiers, le visionnage de vidéos haute définition, les connexions interactives type SSH, l'accès à des sites Web, etc).
La plupart des protocoles de transport normalisés par l'IETF ont du contrôle de congestion. Quand le RFC 5033 a été publié, cela concernait surtout TCP (RFC 9293), avec des outsiders comme DCCP (RFC 4340) ou SCTP (RFC 9260). Mais il y a aussi désormais QUIC (RFC 9000) et RMCAT (RFC 8836).
Parmi les algorithmes de contrôle de la congestion développés
pour l'Internet, on peut citer CUBIC RFC 9438,
Reno RFC 5681, BBR (pas encore de RFC mais il y a un
brouillon, draft-ietf-ccwg-bbr),
et autres.
Le RFC 5033 ne dit pas clairement si on a « le droit » de déployer un nouvel algorithme de contrôle de la congestion sans l'avoir normalisé dans un RFC. En tout cas, en pratique, comme le montre le déploiement de CUBIC et BBR, on n'attend pas le RFC (l'Internet est sans permission), on publie le code, sous une licence libre dans le cas ci-dessus (CUBIC a été surtout porté par sa mise en œuvre dans Linux) et on y va. Pourtant, avoir une spécification écrite et disponible, revue par l'IETF, serait certainement bénéficiaire pour tout le monde, permettant un examen large du nouvel algorithme et de certaines de ses conséquences imprévues.
(Le RFC cite un très bizarre argument comme quoi, dans certaines entreprises, les développeurs ont le droit de lire les RFC mais pas le code source publié sous une licence libre. Je ne suis pas juriste mais cela ressemble à un disjonctage sérieux de la part du juriste qui a prétendu cela.)
Notre RFC 9743 est donc un guide pour les gens qui vont faire cette très souhaitable évaluation des algorithmes de lutte contre la congestion, dans le prolongement du RFC 2914.
Donc, place au guide, en section 3, le centre de ce RFC. Premier objectif, qu'il existe plusieurs mises en œuvre de l'algorithme, et sous une licence libre. Ce n'est pas une obligation (surtout si le RFC décrivant l'algorithme a le statut « Expérimental ») mais c'est souhaité.
En parlant d'algorithmes expérimentaux, le RFC rappelle que la spécification d'un tel algorithme doit indiquer quels résultats on attend de l'expérience, et ce qu'il faudrait pour progresser. La section 12 du RFC 6928 et la section 4 du RFC 4614 sont de bons exemples en ce sens.
Un algorithme expérimental ne doit pas être activé par défaut et doit être désactivable s'il a des comportements désagréables. Mais il faut quand même le tester sinon il ne progressera jamais et ce test peut, au début, être fait dans un simulateur (RFC 8869) mais il doit, à un moment, être fait en vrai grandeur, dans l'Internet réel. Le RFC ajoute donc que tout déploiement ne doit être fait qu'accompagné de mesures qui permettront d'obtenir des informations.
Comme résultat de l'évaluation, tout RFC décrivant un algorithme de contrôle de congestion doit indiquer explicitement, dès le début, s'il est sûr et peut être déployé massivement sans précautions particulières. (Un exemple d'expérimentation figure dans le RFC 3649.)
Une exception est faite par notre RFC sur les « environnements contrôlés » (section 4). Il s'agit de réseaux qui sont sous le contrôle d'une seule organisation, qui maitrise tout ce qui s'y passe, sans conséquences pour des tiers (RFC 8799), et peuvent donc utiliser des algorithmes de contrôle de la congestion qu'on ne voudrait pas voir déployés dans l'Internet public. Un exemple typique d'un tel « environnement contrôlé » est un centre de données privé, avec souvent des commutateurs qui signalent aux machines terminales l'état du réseau, leur permettant d'ajuster leur débit (sur les centres de données, voir aussi la section 7.11).
Une fois passé ce cas particulier, allons voir la section 5, qui est le cœur de ce RFC ; elle liste les critères d'évaluation d'un algorithme de contrôle de la congestion. D'abord, dans le cas relativement simple où plusieurs flux de données sont en compétition sur un même lien mais que tous utilisent l'algorithme évalué. Est-ce que chaque flux a bien sa juste part (qui est une part égale aux autres, lorsque les flux veulent transmettre le plus possible) ? En outre, est-ce que l'algorithme évite l'écroulement qui se produit lorsque, en raison de pertes de paquets, les émetteurs ré-émettent massivement, aggravant le problème ? Pour cela, il faut regarder si l'algorithme ralentit en cas de perte de paquets, voire arrête d'émettre lorsque le taux de pertes devient trop important (cf. RFC 3714). Lire aussi les RFC 2914 et RFC 8961, qui posent les principes de cette réaction à la perte de paquets. Ce critère d'évaluation n'impose pas que le mécanisme d'évitement de la congestion soit identique à celui de TCP.
Une façon d'éviter de perdre les paquets est de les mettre dans une file d'attente, en attendant qu'ils puissent être transmis. Avec l'augmentation de la taille des mémoires, on pourrait penser que cette solution est de plus en plus bénéfique. Mais elle mène à de longues files d'attente, où les paquets séjourneront de plus en plus longtemps, au détriment de la latence, un phénomène connu sous le nom de bufferbloat. Le RFC demande donc qu'on évalue les mécanismes de contrôle de la congestion en regardant comment ils évitent ces longues files d'attente (RFC 8961 et RFC 8085, notez que Reno et CUBIC ne font rien pour éviter le bufferbloat).
Il est bien sûr crucial d'éviter les pertes de paquets ; même si
les protocoles comme TCP savent les rattraper (en demandant une
réémission des paquets manquants), les performances en souffrent, et
c'est du gaspillage que d'envoyer des paquets qui seront perdus en
route. Un algorithme comme la première version de BBR (dans
draft-cardwell-iccrg-bbr-congestion-control-00)
avait ce
défaut de mener à des pertes de paquets. Mais cette exigence
laisse quand même pas mal de marge de manœuvre aux protocoles de
contrôle de la congestion.
Autre exigence importante, l'équité (ou la justice). On la décrit souvent en disant que tous les flux doivent avoir le même débit. Mais c'est une vision trop simple : certains flux n'ont pas grand'chose à envoyer et il est alors normal que leur débit soit plus faible. L'équité se mesure entre des flux qui sont similaires.
En parlant de flux, il faut noter que, comme les algorithmes de contrôle de congestion n'atteignent leur état stable qu'au bout d'un certain temps, les flux courts, qui peuvent représenter une bonne partie du trafic (songez à une connexion TCP créée pour une seule requête HTTP d'une page de petite taille) n'auront jamais leur débit théorique. Les auteurs d'un protocole de contrôle de la congestion doivent donc étudier ce qui se passe lors de flux courts, qui n'atteignent pas le débit asymptotique.
La question de l'équité ne concerne pas que les flux utilisant tous le même algorithme de contrôle de la congestion. Il faut aussi penser au cas où plusieurs flux se partagent la capacité du réseau, tout en utilisant des algorithmes différents (section 5.2). Le principe, lorsqu'on envisage un nouveau protocole, est que les flux qui l'utilisent ne doivent pas obtenir une part de la capacité plus grande que les flux utilisant les autres protocoles (RFC 5681, RFC 9002 et RFC 9438). Les algorithmes du nouveau protocole doivent être étudiés en s'assurant qu'ils ne vont pas dégrader la situation, et ne pas supposer que le protocole sera le seul, il devra au contraire coexister avec les autres protocoles. (Dans un réseau décentralisé comme l'Internet, on ne peut pas espérer que tout le monde utilise le même protocole de contrôle de la congestion.)
Pour compliquer la chose, il y a aussi des algorithmes qui visent à satisfaire les besoins spécifiques des applications « temps réel ». Leur débit attendu est faible mais ils sont par contre très exigeants sur la latence maximale (cf. RFC 8836). La question est étudiée dans les RFC 8868 et RFC 8867 ainsi que, pour le cas spécifique de RTP, dans le RFC 9392. Si on prétend déployer un nouveau protocole de contrôle de la congestion, il doit coexister harmonieusement avec ces protocoles temps réel. La tâche est d'autant plus difficile, note notre RFC, que ces protocoles sont souvent peu ou mal documentés.
Bon, quelques autres trucs à garder en tête. D'abord, il faut évidemment que tout nouveau protocole soit déployable de manière incrémentale. Pas question d'un flag day où tout l'Internet changerait de mécanisme de contrôle de la congestion du jour au lendemain (section 5.3.2). Si le protocole est conçu pour des environnements très spécifiques (comme l'intérieur d'un centre de données privé), il peut se permettre d'être plus radical dans ses choix mais le RFC insiste sur l'importance, dans ce cas, de décrire les mesures par lesquelles on va s'assurer que le protocole n'est réellement utilisé que dans ces environnements. Un exemple de discussion sur le déploiement incrémental figure dans les sections 10.3 et 10.4 du RFC 4782.
La section 6 de notre RFC rappelle que le protocole doit être
évalué dans des environnements différents qu'on peut rencontrer sur
l'Internet public. Ainsi, les liaisons filaires se caractérisent par
une très faible quantité de perte de paquets, sauf dans les routeurs,
lorsque leur file d'attente est pleine. Et leurs caractéristiques sont
stables dans le temps. En revanche, les liens sans fil ont des
caractéristiques variables (par exemple en fonction d'évènements
météorologiques) et des pertes de paquets en route, pas seulement
dans les routeurs. Le RFC 3819 et le
brouillon draft-irtf-tmrg-tools
(dans sa section 16) discutent ce problème, que l'algorithme de
contrôle de congestion doit prendre en compte.
Tout cela est bien compliqué, vous allez me dire ? Mais ce n'est pas fini, il reste les « cas spéciaux » de la section 7. D'abord, si le routeur fait de l'AQM, c'est-à-dire jette des paquets avant que la file d'attente ne soit pleine. Des exemples de tels algorithmes sont Flow Queue CoDel (RFC 8290), PIE (Proportional Integral Controller Enhanced, RFC 8033) ou L4S (Low Latency, Low Loss, and Scalable Throughput, RFC 9332). L'évaluation doit donc tenir compte de ces algorithmes.
Certains réseaux disposent de disjoncteurs (breakers, RFC 8084), qui surveillent le trafic et coupent ou réduisent lorsque la congestion apparait. Là encore, tout nouvel algorithme de contrôle de la congestion qu'on utilise doit gérer le cas où de tels disjoncteurs sont présents.
Autre cas qui complique les choses, les réseaux à latence variable. Avec un réseau simple, la latence dans les câbles est fixe et la latence vue par les flux ne varie qu'avec l'occupation des files d'attentes du routeur. Mais un chemin à travers l'Internet n'est pas simple, et la latence peut varier dans le temps, par exemple parce que les routes changent et qu'on passe par d'autres réseaux. (Voir par exemple les conséquences d'une coupure de câble.) Bref, le protocole de contrôle de la congestion ne doit pas supposer une latence constante. En parlant de latence, il y a aussi des liens qui ont une latence bien plus élevée que ce que qu'attendent certains protocoles simples. C'est par exemple le cas des liens satellite (RFC 2488 et RFC 3649). Et en parlant de variations, l'Internet voit souvent des brusques changements, par exemple un brusque afflux de paquets, et notre protocole devra gérer cela (section 9.2 du RFC 4782). J'avais dit que l'Internet était compliqué !
Et pour ajouter à cette complication, il y a des réseaux qui changent l'ordre des paquets. Oui, vous savez cela. Tout le monde sait qu'IP ne garantit pas l'ordre d'arrivée des paquets. Tout le monde le sait mais notre RFC juge utile de le rappeler car c'est un des défis que devra relever un protocole de contrôle de la congestion : bien fonctionner même en cas de sérieux réordonnancement des paquets, comme discuté dans le RFC 4653.
L'algorithme utilisé pour gérer la congestion ne doit pas non plus être trop subtil, car il faudra qu'il puisse être exécuté par des machines limitées (en processeur, en mémoire, etc, cf. RFC 7228).
Le cas où un flux emprunte plusieurs chemins (Multipath TCP, RFC 8684, mais lisez aussi le RFC 6356) est délicat. Par exemple, on peut avoir un seul des chemins qui est congestionné (le protocole de gestion des chemins peut alors décider d'abandonner ce chemin) mais aussi plusieurs chemins qui partagent le même goulet d'étranglement.
Et, bien sûr, l'Internet est une jungle. On ne peut pas compter que toutes les machines seront gérées par des gentilles licornes arc-en-ciel bienveillantes. Tout protocole de contrôle de la congestion déployé dans l'Internet public doit donc tenir compte des méchants. (Il y a aussi, bien plus nombreux, les programmes bogués et les administrateurs système incompétents. Mais, si un protocole tient le coup en présence d'attaques, a fortiori, il résistera aux programmes non conformes.) Une lecture intéressante est le RFC 4782, dans ses sections 9.4 à 9.6.
L'annexe A résume les changements depuis le RFC 5033. Il y a notamment :
- L'ajout de QUIC,
- un texte plus précis sur le bufferbloat,
- le cas des machines contraintes (pour l'IoT),
- des discussions sur l'AQM, les flux courts, le temps réel…
L'article seul
RFC 9741: Concise Data Definition Language (CDDL): Additional Control Operators for the Conversion and Processing of Text
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 5 mars 2025
Le langage CDDL, qui permet de créer un schéma formel pour des formats comme CBOR, peut s'étendre via l'ajout d'« opérateurs de contrôle ». Ce RFC en spécifie quelques uns, notamment pour agir sur du texte ou convertir d'une forme dans une autre.
CDDL est normalisé dans le RFC 8610. Sa principale utilisation est pour fournir des schémas afin de valider des données encodées en CBOR (RFC 8949). Du fait de l'extensibilité de CDDL (voir notamment RFC 8610, section 3.8), le RFC 9165 a pu ajouter l'addition, la concaténation, etc. Notre nouveau RFC 9741 ajoute encore d'autres opérateurs, surtout de conversion d'une représentation dans une autre.
Je ne vais pas tous les citer ici (lisez le RFC), juste donner
quelques exemples. D'abord, .b64u, qui va
convertir une chaine d'octets en sa représentation en
Base64 (RFC 4648 et,
rassurez-vous, il y a aussi des opérateurs pour
Base32 et les autres).
Voici un exemple. Mais d'abord, on installe l'outil cddl. Écrit en Ruby, il s'installe avec :
% gem install cddl
Ensuite, on écrit un schéma CDDL utilisant l'opérateur
.b45 (Base45 est
normalisé dans le RFC 9285) :
% cat base.cddl encoded = text .b45 "Café ou thé ?"
En utilisant les fonctions de génération de l'outil cddl, on trouve :
% cddl base.cddl generate "EN8R:C6HL34ES44:AD6HLI1"
C'est bien l'encodage en Base45 de la chaine de caractères utilisée (évidemment, dans un vrai schéma, on utiliserait une variable, pas une chaine fixe).
Ensuite, .printf va formater du texte, en
utilisant les descriptions de format du printf de
C.
% cat printf.cddl my_alg_19 = hexlabel<19> hexlabel<K> = text .printf (["0x%04x", K]) % cddl printf.cddl generate "0x0013"
Bien sûr, ce n'est pas la méthode la plus simple pour convertir le 19 décimal en 13 hexadécimal. Mais le but est simplement d'illustrer le fonctionnement des nouveaux opérateurs.
Enfin, .join va transformer un tableau en
chaine d'octets.
Voici l'exemple du RFC, avec des adresses
IPv4 :
% cat address.cddl
legacy-ip-address = text .join legacy-ip-address-elements
legacy-ip-address-elements = [bytetext, ".", bytetext, ".",
bytetext, ".", bytetext]
bytetext = text .base10 byte
byte = 0..255
% cddl address.cddl generate
"108.58.234.211"
% cddl address.cddl generate
"42.65.53.156"
% cddl address.cddl generate
"77.233.49.115"
Les nouveaux opérateurs ont été placés dans le registre
IANA. Ils sont mis en œuvre dans l'outil de référence de CDDL
(le cddl utilisé ici). Écrit en
Ruby, on peut l'installer avec la méthode
Ruby classique :
% gem install cddl
Il existe une autre mise en œuvre de CDDL (qui porte malheureusement le même nom). Elle est en Rust et peut donc s'installer avec :
% cargo install cddl
Elle n'inclut pas encore les opérateurs de ce RFC :
% ~/.cargo/bin/cddl validate --cddl schema.cddl --json person.json Error: "error: lexer error\n ┌─ input:7:26\n │\n7 │ legacy-ip-address = text .join legacy-ip-address-elements\n │ ^^^^^ invalid control operator\n\n"
L'article seul
RFC 9583: Application Scenarios for the Quantum Internet
Date de publication du RFC : Juin 2024
Auteur(s) du RFC : C. Wang (InterDigital Communications), A. Rahman (Ericsson), R. Li (Kanazawa University), M. Aelmans (Juniper Networks), K. Chakraborty (The University of Edinburgh)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF qirg
Première rédaction de cet article le 27 février 2025
Peut-être, dans le futur, nous aurons un Internet quantique, où les communications utiliseront à fond les surprenantes propriétés de la physique quantique. Ce RFC se penche sur les applications que cela pourrait avoir, et les utilisations possibles.
Un Internet quantique, décrit dans le RFC 9340, ce serait un Internet où les machines terminales et les routeurs utiliseraient des propriétés purement quantiques, comme l'intrication. Ces divers engins seraient reliés par des liens, par exemple des photons circulant en dehors de tout câble, une configuration bien adaptée à l'utilisation de la quantique. Si vous voulez apprendre plus en détail ce que pourrait être un Internet quantique, voyez l'article de Wehner, S., Elkouss, D. et R. Hanson, « Quantum internet: A vision for the road ahead », publié dans Science. Rappelons qu'il n'y a pas de perspective réaliste de grand remplacement de l'Internet classique : l'Internet quantique va venir en plus, pas à la place.
À quoi va pouvoir servir un Internet quantique ? On peut imaginer, par exemple, des calculs quantiques répartis, ou de la synchronisation d'horloges atomiques.
Un peu de terminologie, ensuite. La section 2 du RFC définit les termes importants. Ce sont ceux du RFC 9340 plus, notamment :
- Qubit : unité d'information en calcul quantique. Sa valeur, quand on le mesure, est 0 ou 1, comme un bit classique mais, tant qu'il n'a pas été mesuré, ce n'est qu'une probabilité. Diverses particules élémentaires peuvent être utilisées pour faire un qubit, par exemple les photons et, pour chaque particule, tout degré de liberté (comme le spin) peut servir à encoder le qubit.
- Paires de Bell : deux qubits intriqués, par exemple (en utilisant la notation de Dirac) (|00>+|11>)/Sqrt(2).
- NISQ (Noisy Intermediate-Scale Quantum) : l'état actuel des calculateurs quantiques, petits et faisant plein d'erreurs.
- « Préparer et mesurer » : se dit des protocoles quantiques les plus simples, où on prépare des qubits et où on les mesure ensuite. Le protocole de distribution quantique de clés BB84 est un exemple.
- Téléportation : déplacer quantiquement un qubit d'un point à un autre (c'est moins évident que pour déplacer un bit). Notez qu'il existe une différence subtile entre téléporter un qubit et le transmettre mais l'explication de cette différence est au-dessus de mes forces.
Revenons maintenant aux applications, le but de ce RFC. Il y a plusieurs catégories :
- Cryptographie quantique (terme sans doute excessif - il s'agit plutôt d'aider des opérations cryptographiques par la quantique - mais largement utilisé),
- Capteurs quantiques,
- Calcul quantique.
Voyons-les dans l'ordre. D'abord, utilisations de la quantique pour aider la cryptographie. (Au passage, la cryptographie post-quantique est tout le contraire : elle utilise des calculateurs classiques pour faire de la cryptographie qui résiste aux calculateurs quantiques.) Cela inclut :
- Distribution quantique de clés (dont j'ai déjà dit du mal).
- Négociation byzantine rapide : une solution quantique au problème des généraux byzantins.
- Argent quantique : la quantique peut tout, même gérer de l'argent. Plus fort que les cryptomonnaies ! Après tout, une propriété essentielle des états quantiques est le fait qu'on ne puisse pas les copier. C'est certainement utile pour l'argent mais ce n'est pas facile à faire (cf. les attaques décrites dans « Cryptanalysis of Three Quantum Money Schemes »).
Il y a aussi des capteurs quantiques ; intriqués, ils permettent des mesures particulièrement sensibles (voir « Multiparameter Estimation in Networked Quantum Sensors » ou, par exemple, pour la synchronisation d'horloges, « A quantum network of clocks »).
On connait également les possibilités de la physique quantique pour le calcul, notamment via la possibilité de casser des algorithmes de cryptographie. On peut envisager des calculateurs quantiques répartis, où plusieurs calculateurs séparés travailleraient ensemble, donnant l'impression d'un calculateur unique. Il pourrait également exister du calcul quantique en aveugle, où le calcul serait fait sur des données, sans avoir les données en question, ce qui serait utile pour la confidentialité. (Oui, cela semble magique, mais c'est souvent comme cela dans le monde quantique, et ce calcul en aveugle est détaillé dans la section 4.2. Voir « Private quantum computation: an introduction to blind quantum computing and related protocols ».)
La section 4 présente ensuite des scénarios d'usage plus détaillés, par exemple sur la distribution quantique de clés (voir l'article sceptique de l'ANSSI), le calcul en aveugle et le calcul quantique réparti.
Tout cela est bien joli mais, pour passer de ces applications futuristes à un vrai Internet quantique, il faut des machines, et les connecter. La section 5 du RFC détaille ce qui sera nécessaire pour ce déploiement. Actuellement, on a quelques centaines de qubits physiques dans les plus gros calculateurs (et ce sont des NISQ, avec beaucoup d'erreurs), ce qui est très insuffisant. Suivant la classification de Wehner, le RFC cite six étapes possibles vers un Internet quantique :
- Première étape, des répéteurs de confiance (et donc pas de sécurité de bout en bout, c'est la situation actuelle de pas mal de réalisations quantiques lourdement vantées dans les médias ignorants, dans les articles technobéats sur la QKD),
- Deuxième étape, quand l'utilisateur final peut lui-même préparer et mesurer des qubits,
- Ensuite, chemin quantique de bout en bout, donc de la vraie distribution quantique de clés, par exemple,
- À la quatrième étape, les répéteurs peuvent agir sur les qubits (section 5.1 pour les détails), ce qui permettra plein d'autres applications comme le calcul en aveugle,
- Puis ils deviennent capables de correction d'erreurs, ce qui évite de consommer plein de qubits physiques pour faire un qubit logique,
- Et enfin, sixième et dernière étape, quand le nombre de qubits sera suffisant pour faire toutes les applications dont on rêve.
Cette image vient de l'article « Quantum
internet: A vision for the road ahead : 
Comme toujours dans un RFC, il y a une section sur la sécurité, qui douche toujours un peu les espoirs. Ce n'est pas tout de communiquer, il faut aussi le faire de manière sûre. Si la distribution quantique de clés résiste à toute tentative d'espionnage (elle est protégée par la physique, et pas par la mathématique mais attention quand même), une autre technologie quantique fait courir des risques à la cryptographie, les calculateurs quantiques peuvent casser des algorithmes très utilisés comme RSA et ECDSA. Dans un monde (très futuriste…) où on aurait des calculateurs quantiques significatifs (CRQC = Cryptographically Relevant Quantum Computers) reliés par un réseau quantique pour qu'ils se partagent les calculs, toutes les clés RSA du monde seraient cassées rapidement. Il est donc important de travailler dès maintenant sur la cryptographie post-quantique.
À ce stade, la constatation est que malheureusement nous n'avons pas encore d'Internet quantique pour faire des ping et des traceroute…
L'article seul
RFC 9707: IAB Barriers to Internet Access of Services (BIAS) Workshop Report
Date de publication du RFC : Février 2025
Auteur(s) du RFC : M. Kühlewind, D. Dhody, M. Knodel
Pour information
Première rédaction de cet article le 26 février 2025
L'Internet est aujourd'hui un service indispensable à toutes les activités humaines. Un accès correct à ce réseau est donc crucial. Mais plusieurs problèmes limitent l'accès à l'Internet ou à plusieurs de ses services. L'IAB avait organisé en janvier 2024 un atelier sur cette question, atelier dont ce RFC est le compte-rendu.
Trois thèmes principaux étaient à l'agenda de cet atelier, qui s'est tenu entièrement en ligne : l'état de la fracture numérique, le rôle des réseaux communautaires et la question de la censure. Oui, il y aurait eu plein d'autres thèmes possibles (comme les difficultés d'accès aux services en ligne, par exemple parce que leur utilisation est anormalement difficile) mais en trois jours d'atelier, ce n'est déjà pas mal.
Comme tous les ateliers de l'IAB, celui-ci a fonctionné en demandant aux participants des position papers expliquant leur point de vue. Ne participent à l'atelier que des gens ayant écrit un de ces articles, ce qui garantit que tout le monde a dû travailler le sujet. Ces articles sont disponibles en ligne.
Le RFC commence en rappelant que, dans une société où tout se fait via l'Internet, ne pas avoir accès à l'Internet, ou bien n'avoir un accès que dans de mauvaises conditions, est une discrimination inacceptable. Le RFC insiste sur ce deuxième point : aujourd'hui, le problème n'est plus uniquement l'absence totale d'accès Internet, c'est souvent l'accès de mauvaise qualité (liaison trop lente, intermittente, ordinateur trop lent pour les sites Web modernes surchargés de gadgets, censure, etc). L'atelier de l'IAB visait à :
- récolter des informations sur les diverses inégalités d'accès,
- mieux comprendre les différentes façons dont les gens accèdent à l'Internet (et pas uniquement dans les pays riches),
- et ce que veut dire « être connecté à l'Internet » pour les utilisateurs, quels sont leurs usages et leurs exigences.
Le premier jour, l'atelier a surtout travaillé sur les réseaux dits « communautaires » (terminologie très étatsunienne, je m'excuse mais c'est celle du RFC). Ces réseaux bâtis localement par leurs utilisateurices, sans but lucratif, sont décrits plus en détail dans le RFC 7962 et un groupe de recherche IRTF existe, GAIA. Le plus connu et le plus souvent cité est Guifi. Ces réseaux communautaires souffrent de divers problèmes, dont bien sûr le coût élevé du transit, qui est nécessaire pour joindre le reste de l'Internet. Une des pistes évoquées était l'installation des CDN dans ces réseaux communautaires, pour limiter l'utilisation du transit. Cette piste était par exemple citée dans cette intervention, dont on notera qu'un des auteurs travaille pour un CDN, qui a par ailleurs un projet caritatif pour les réseaux communautaires. Opinion personnelle : c'est très discutable, les CDN ne servent qu'à la consommation passive de contenu et, pire, renforcent le contenu déjà très populaire.
L'accès au transit peut se faire par liaison terrestre fixe mais aussi par satellite, les satellites en orbite basse (LEO) étant actuellement en plein développement. Notez que cela ne résout pas les problèmes de contrôle, comme l'a montré la coupure de l'Ukraine par Starlink.
Le RFC note aussi un problème social : les opérateurs des réseaux communautaires sont peu présents à l'IETF et donc leurs questions et problèmes ne sont pas forcément bien pris en compte dans la normalisation technique.
Autre sujet, le deuxième jour, la fameuse fracture numérique. Comme dit plus haut, elle ne se réduit pas au fait de ne pas avoir d'accès du tout, problème qu'on pourrait régler en posant de la fibre optique. Il y a aussi une fracture entre celleux qui accèdent à l'Internet dans de bonnes conditions et celleux qui sont du mauvais côté de la fracture. Des bonnes conditions, cela concerne à la fois la technique (liaison rapide et fiable) mais aussi la maitrise de son activité en ligne (ne pas être dépendant des GAFA, par exemple, ce que le RFC ne mentionne guère).
À l'atelier, Holz a par exemple étudié les serveurs DNS faisant autorité pour divers domaines australiens et montré que les organisations indigènes étaient nettement moins bien servies.
Les différentes personnes vivant sur Terre parlant de nombreuses langues différentes, la question de la possibilité de chacun·e d'utiliser sa langue a toute sa place dans toute discussion sur les inégalités d'accès. D'où l'exposé de Hussain sur le projet Universal Acceptance de l'ICANN, qui vise à faire en sorte que, par exemple, les noms de domaine en Unicode soient acceptés partout. Actuellement, si le travail de normalisation est largement fini, le déploiement effectif est loin d'être complet. (Opinion personnelle : cette question de l'acceptation universelle des TLD ICANN en Unicode n'est qu'une toute petite partie de la question des langues sur l'Internet.)
Il y a aussi le problème des performances : bien des sites Web modernes sont développées par une personne riche et bien connectée, munie d'un ordinateur rapide. Ils sont souvent pénibles à utiliser lorsque la liaison est lente et/ou la machine de l'utilisateur un peu ancienne. (Et, dans mon expérience, les remarques aux développeurs Web sur ce point sont souvent accueillies par des remarques méprisantes.) L'étude de Habib et al. analyse très bien ce problème, notamment pour les pays « du Sud » (et propose une solution technique mais, quoi qu'on pense de cette solution, l'étude reste très pertinente). Sinon, le RFC n'en parle pas, mais ce problème est une des motivations du projet Gemini.
Gros morceau pour la troisième session, la censure. C'est évidemment un des principaux obstacles sur la route des utilisateurices. Ainsi, le projet iMAP (rien à voir avec IMAP) a documenté la censure dans plusieurs pays asiatiques, notamment en utilisant les sondes OONI. De nombreuses techniques différentes sont utilisées, par exemple des résolveurs DNS menteurs, ou bien, plus sophistiqué, une interférence avec les connexions HTTPS, utilisant le SNI pour repérer le site visité. Parfois, l'utilisateurice est redirigé·e vers une page expliquant le blocage (comme je l'avais vu il y a déjà seize ans à Dubaï, la censure n'est pas une invention récente). Parfois, la censure est plus hypocrite et ne s'avoue pas comme telle.
Une autre étude détaillée est celle de Grover, portant notamment sur l'Inde et le Pakistan. Il insiste notamment sur le caractère inégal de la mise en œuvre de la censure, bien des ressources n'étant bloquées que par certains FAI.
Évidemment, en Russie, la guerre avec l'Ukraine est le prétexte pour un durcissement considérable de la censure. Basso l'a étudié avec OONI. Notez que son étude montre des domaines bloqués sans être pour autant sur la liste officielle de blocage.
Comme la censure, comme dans ce cas russe, est souvent hypocrite, voire dissimulée, il y a beaucoup de travail à faire du point de vue technique pour l'analyser. C'est ainsi que Wang et al ont présenté les solutions utilisables pour cela. (Et le problème est complexe !)
Tous les intervenants sur la question de la censure ont insisté sur l'importance de l'information des utilisateurices, souvent laissé·es délibèrement dans le noir sur les raisons d'un blocage ou même sur sa simple existence. Les solutions normalisées existantes pour cela incluent le code de retour 451 de HTTP (normalisé dans le RFC 7725) ou les codes EDE, notamment le code 16, pour le DNS (normalisés dans le RFC 8914). Voici deux exemples, respectivement par Google et par Cloudflare, vus en juillet 2024, à propos de la censure en France de sites qui diffusent des spectacles sportifs en violation des intérêts financiers des entreprises comme Canal+ :
% dig @8.8.8.8 tarjetarojatvlive.net … ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 7912 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ; EDE: 16 (Censored): (The requested domain is on a court ordered copyright piracy blocklist for FR (ISO country code). To learn more about this specific removal, please visit https://lumendatabase.org/notices/41939614.) … ;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP) ;; WHEN: Wed Jul 03 10:34:44 CEST 2024
% curl -v jokersportshd.net … * Connected to jokersportshd.net (2606:4700:3034::6815:5b9) port 80 (#0) > GET / HTTP/1.1 > Host: jokersportshd.net > User-Agent: curl/7.81.0 > Accept: */* … < HTTP/1.1 451 < Date: Wed, 03 Jul 2024 08:36:59 GMT < Content-Type: text/html … <!DOCTYPE html><html class="no-js" lang="en-US"> <head> <title>Unavailable For Legal Reasons</title> … <p>This website is unavailable for legal reasons.</p><p>Please see <a rel="noopener noreferrer" href="https://lumendatabase.org/notices/42038946" target="_blank">https://lumendatabase.org/notices/42038946</a> for more details.</p> ..
(Il y aurait aussi le RFC 6108, mais il est aujourd'hui techniquement dépassé.) Les mécanismes standardisés pour signaler une censure sont peu utilisés aujourd'hui, et les explications sont rares.
Notons que rediriger les utilisateurs vers une page Web d'information leur annonçant qu'ils ont été bloqués (comme le fait en France la Main Rouge) est dangereux : cela permet au gestionnaire de la page en question de voir l'adresse IP (et d'autres informations envoyées par le navigateur) du visiteur ou de la visiteuse. En France, le ministère de l'Intérieur avait ainsi supprimé les données récoltées… après avoir juré qu'il n'en récoltait pas !
Qui dit censure dit évidemment contournement, car les utilisateurices ne vont pas rester les bras ballants face aux mesures de blocage. Ont été discutés à l'atelier les VPN, par exemple, y compris leurs problèmes actuels (cf. l'excellente étude de Ramesh sur les VPN et leurs limites, à lire la prochaine fois qu'un youtubeur vous fera la pub de NordVPN).
Voilà, maintenant, il y a du travail pour des groupes IRTF comme GAIA, HRPC, PEARG, et MAPRG (section 2.4 du RFC, sur le travail à faire).
L'article seul
Fiche de lecture : Si Einstein avait su
Auteur(s) du livre : Alain Aspect
Éditeur : Odile Jacob
978-2-4130-0702-7
Publié en 2025
Première rédaction de cet article le 24 février 2025
Alain Aspect raconte dans ce livre l'histoire des expériences qu'il a menées dans les années 1970-1980 et qui ont prouvé la violation des inégalités de Bell (en termes journalistiques « prouvé qu'Einstein avait tort »). Attention, il faut s'accrocher, mais c'est très bien décrit.
Bon, alors, avant que vous ne commandiez le livre, je vous dis tout de suite qu'à mon avis il faut au moins un bac scientifique et ne pas avoir tout oublié depuis. Comme le dit l'auteur au détour d'une page « Elles [ces démonstrations mathématiques] sont au demeurant peu difficiles sur le plan technique, et particulièrement limpides si on sait les suivre. » C'est un gros si…
Mais cela vaut la peine. Car l'auteur raconte une passionnante aventure scientifique, dont il a été un des principaux protagonistes. Dans les années 1920, la physique quantique prend forme et un formalisme mathématique est développé, qui permet des calculs qui collent parfaitement avec les expériences. Donc, tout va bien, on a compris comment le monde marchait, et on peut réduire les budgets de la recherche en physique ? Non car, si la plupart des physiciens sont très contents que la quantique marche aussi bien et se satisfont de ce formalisme, Einstein râle : le fait qu'au cœur de la quantique, il n'y ait que des probabilités et pas de certitudes lui semble bancal. Il doit y avoir quelque chose sous la quantique qui permet de retrouver son formalisme. Bohr n'est pas d'accord, il pense que le caractère probabiliste de la quantique n'est pas le résultat de notre ignorance mais une propriété fondamentale. Tout le monde cite ce débat des années 1920 et 1930 comme la controverse Einstein-Bohr et, en effet, à part ces deux chercheurs, peu de physiciens se sentent concernés ; la quantique marche, c'est tout ce qu'on lui demande. Le débat Einstein-Bohr semble purement philosophique, puisqu'il n'a pas de conséquences pratiques : tout le monde est d'accord que les calculs faits avec le formalisme quantique donnent le bon résultat. Alors, savoir s'il y a quelque chose en dessous semble de peu d'intérêt (Aspect rencontrera souvent cette attitude quand il commencera à s'intéresser au sujet des dizaines d'années plus tard).
Une étape importante survient en 1964 quand Bell démontre que le problème n'est pas purement philosophique et qu'il peut être tranché par l'expérience : il établit des relations entre certaines valeurs qui sont respectées par toute théorie non probabiliste mais seraient violées par la quantique. Il ne reste « plus qu'à » tester ces relations. Mais Bell publie dans un journal peu connu et qui cessera vite de paraitre. Son article passe donc assez inaperçu (et l'Internet n'existait pas alors, c'était journaux papier et photocopies si on voulait diffuser la connaissance).
Dans les années 1970, toutefois, plusieurs équipes commencent à monter des expériences pour tester les inégalités de Bell. Elles sont très difficiles à mesurer et les premiers résultats ne sont pas très concluants, voire contradictoires. (En science, l'expérience a toujours raison ; mais que faire si deux expériences donnent des résultats contraires ?) C'est à ce moment qu'Alain Aspect se penche sur le sujet. Son livre, après avoir exposé en détail le problème qu'on essayait de résoudre (en très simplifié : est-ce Einstein ou Bohr qui avait raison ?), décrit l'expérience ou plutôt les expériences, qui finalement trancheront la question. (Divulgâchage : les inégalités de Bell sont violées, le formalisme quantique était donc tout ce qui comptait et son caractère probabiliste est fondamental.)
La réalisation de l'expérience a nécessité plusieurs tours de force, racontés dans le livre. (Vous y apprendrez pourquoi il faut beaucoup de sable pour vérifier la physique quantique.) À chaque résultat, des objections pouvaient être élevées. Par exemple, les deux instruments qui filtrent les photons émis (les polariseurs), avant leur mesure, sont censés être indépendants. Mais peut-être se coordonnent-ils d'une manière inconnue ? Pour éliminer cette possibilité, il faut alors modifier l'expérience pour déplacer les instruments en moins de temps qu'il n'en faut à la lumière pour aller de l'un à l'autre, afin d'être sûr qu'ils n'ont pas pu se coordonner. (Vous noterez que cela utilise un résultat connu d'Einstein : la vitesse de la lumière ne peut pas être dépassée.) À la fin, tout le monde s'y rallie : aucune échappatoire, la quantique, dans l'interprétation qu'en faisait Bohr, est bien gagnante (il a fallu encore quelques expériences après celles d'Aspect). Mais il y a quand même une partie amusante à la fin du livre, sur les possibilités que « quelque chose » intervienne et explique les résultats qui semblaient probabilistes. La science n'est jamais 100 % terminée.
Tout cela s'est étalé sur plusieurs années, compte tenu de l'extrême délicatesse des phénomènes physiques à mesurer. Comme le conseillait un expert consulté par Aspect au début « ne vous lancez pas là-dedans si vous n'avez pas un poste stable, avec sécurité financière ».
Et le titre du livre, alors ? L'opinion d'Aspect est qu'Einstein, avec ces expériences, aurait admis que la physique quantique donnait bien une description complète. Les erreurs sont importantes en science, ici, elles ont poussé à creuser la question, et j'ai appris dans ce livre que l'intrication quantique, une des propriétés les moins intuitives du monde quantique, avait justement été mise en évidence par Einstein, lors de ce débat. Voulant trouver un cas « absurde » pour appuyer son point de vue, il a découvert quelque chose de très utile.
Lors de la présentation du livre à la librairie Le Divan à Paris, le 14 février, un spectateur a demandé à Aspect son opinion sur les calculateurs quantiques, qui utilisent justement l'intrication. « Il [le calculateur quantique] marche car il y a davantage d'informations dans des particules intriquées que la somme de leurs informations. Mais il n'existe aujourd'hui aucun vrai ordinateur quantique. Trop d'erreurs et pas assez de corrections (1 000 qubits réels pour faire un seul qubit logique correct). »
La vidéo de la
présentation à la librairie Le Divan (animée par Anna Niemiec, de la
chaine Space Apéro), est visible en
ligne. 
L'article seul
Fusion thermonucléaire et interprétation des annonces
Première rédaction de cet article le 20 février 2025
Le 18 février, le CEA a annoncé avoir battu un record de durée de confinement pour du plasma. Aussitôt, des dizaines de personnes ont écrit des messages techno-béats et anti-écologistes, sans prendre la mesure de ce qui avait été réalisé et de ce qui reste à faire. Petite discussion sur cette réactivité des technosolutionnistes, ces gens qui espèrent résoudre tous les problèmes de l'humanité par une invention technique spectaculaire.
Je n'ai pas l'impression qu'il y ait eu une publication un peu détaillée du résultat obtenu le 12 février (à part un tweet et un article qui explique le contexte mais pas tellement le résultat obtenu). Si vous avez trouvé, les détails m'intéressent. Bon, en très bref, les chercheur·ses (et technicien·nes et ouvrier·ères) ont réussi à garder dans un tokamak un plasma très chaud (vraiment très chaud) pendant une durée plus longue que le record précédent, et ce résultat est une étape dans l'obtention, à très long terme, d'un réacteur de production d'énergie par fusion thermonucléaire. C'est très cool du point de vue scientifique.
Mais ce qui m'a frappé, ce sont les réactions de certains. Bon,
d'accord, c'était sur Twitter, qui n'est pas
connu pour l'intelligence et la sensibilité de ses
utilisateurices. Pour ceux et celles qui ne connaissent pas, voici
le genre de tweets de réponse qu'on voit quand une journaliste
experte en géopolitique écrit une analyse sérieuse (sur un autre
sujet) : 
Cela donne une bonne idée du niveau moyen du débat sur
Twitter. Compte-tenu de cela, ne soyons pas trop étonnés de voir
arriver des tweets chauvins :
Ou bien très techno-béats :

Mais, surtout, il y a des gens qui jettent le masque ; le succès
du CEA n'est pour eux qu'un prétexte pour dire leur haine des
écologistes :
Idem ici : 
Évidemment, ce que disent les écologistes, et tous les scientifiques est gênant. Alors, il est tentant de défendre son confort intellectuel en attaquant violemment le messager plutôt que de lire le message. C'est puéril, mais fréquent, comme par exemple chez les gens qui disent qu'ils ne veulent pas d'« écologie punitive » ; ce n'est pas l'écologie qui est punitive, c'est la physique ! (Ou, pour citer le proverbe breton, « Le capitaine qui ne veut pas obéir à la carte finira par obéir aux récifs. ».)
Outre ces tweets haineux contre tout ce qui pourrait menacer leur
droit sacré à rouler en voiture tant qu'ils veulent, on voit aussi
des tweets technosolutionnistes, de gens qui
espèrent qu'un progrès scientifique leur évitera de changer leur
mode de vie : 
Le plus amusant est que ces gens qui se réclament de la science et accusent les écologistes d'obscurantisme font preuve d'une grande ignorance de la science. Cela fait des dizaines d'années qu'on nous affirme que la recherche sur la fusion thermonucléaire va déboucher sur une énergie gratuite, illimitée et non polluante, et à court terme. Et il n'y a toujours rien d'opérationnel (le tokamak du record n'a pas du tout produit d'énergie ; ce n'est pas son rôle). Le problème est très complexe (et je ne blâme donc pas les chercheur·ses, technicien·nes et ouvrier·ères, leur tâche est vraiment difficile) et il s'agit de recherche fondamentale bien plus que d'ingéniérie. Le calendrier est donc impossible à prévoir. Il est à noter que les gens qui se sont félicités de la disponibilité prochaine de l'énergie de fusion n'ont même pas fait l'effort de lire le court article du CEA, qui disait très bien, et très honnêtement, « Pour autant, compte-tenu des infrastructures nécessaires pour produire cette énergie à grande échelle, il est peu probable que les technologies de fusion contribuent significativement à l’atteinte du net 0 d’émissions de CO₂ en 2050. Il faudra pour cela lever plusieurs verrous technologiques, mais aussi démontrer la faisabilité économique d’une telle production d’électricité. »
Notons qu'une telle avalanche de messages anti-écologistes et de style trumpiste avait déjà eu lieu en 2023, avec le LK-99, soi-disant à supraconducteur à température ambiante. Les techno-béats n'ont rien appris de cette bavure.
L'article seul
RFC 9535: JSONPath: Query Expressions for JSON
Date de publication du RFC : Février 2024
Auteur(s) du RFC : S. Gössner (Fachhochschule Dortmund), G. Normington, C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jsonpath
Première rédaction de cet article le 14 février 2025
Le langage JSONPath sert à désigner une partie d'un document JSON. Il est donc utile pour, par exemple, extraire des valeurs qui nous intéressent.
Il existe de nombreux langages pour cela (une liste partielle figure à la fin de l'article), pas forcément normalisés mais mis en œuvre dans tel ou tel logiciel (dont, évidemment, jq). Ce RFC est, je crois, la première normalisation formelle d'un tel langage. Voici tout de suite un exemple, utilisant le logiciel jpq, sur la la base des arbres parisiens :
% jpq '$[*].libellefrancais' arbres.json [ "Marronnier", "Aubépine", "Cerisier à fleurs", …
Cela se lit « affiche les noms d'espèce
[libellefrancais, dans le fichier] de tous
[vous avez vu l'astérisque] les
arbres ». (Avec jq, on aurait écrit jq
'.[].libellefrancais' arbres.json.) Voyons maintenant les
détails.
JSONPath travaille sur des
documents JSON, JSON étant normalisé dans le RFC 8259. Il n'est sans doute pas utile de
présenter JSON, qui est utilisé partout aujourd'hui. Notons
simplement que l'argument d'une requête JSONPath, écrit en JSON, est
ensuite modélisé comme un arbre, composé de
nœuds. Le JSON {"foo": 3, "bar": 0} a ainsi une
racine de l'arbre sous laquelle se trouvent deux nœuds, avec comme
valeur 3 et 0 (les noms des membres JSON, foo
et bar, ne sont pas sélectionnables par
JSONPath et donc pas considérés comme nœuds).
Vous êtes impatient·e de vous lancer ? On va utiliser le logiciel jpq cité plus haut. Pensez à installer un Rust très récent puis :
cargo install jpq
Ou bien, si vous voulez travailler à partir des sources :
git clone https://codeberg.org/KMK/jpq.git cd jpq cargo install --path .
Puis pensez à modifier votre chemin de recherche d'exécutables si ce n'est pas déjà fait (notez que l'excellente Julia Evans vient justement de faire un très bon article sur ce sujet). Testez :
% echo '["bof"]' | jpq '$[0]' [ "bof" ]
Les choses utiles à savoir pour écrire des expressins JSONPath :
- Le dollar indique la racine de l'arbre JSON.
- L'expression JSONPath est faite de
segments, chaque segment permettant de
filtrer une partie du document JSON (dans l'exemple immédiatement
au-dessus,
[0]est un segment sélectionnant le premier élément d'un tableau, ici, le seul). - Des sélecteurs sont utilisés dans les segments pour sélectionner via le nom d'un membre JSON ou via un indice (0 dans l'exemple plus haut).
La grammaire complète (en ABNF, RFC 5234) figure dans l'annexe A du RFC.
Allez, passons aux exemples, avec les arbres parisiens comme document JSON. Le quatrième arbre du document (on part de zéro) :
% jpq '$[3]' arbres.json
[
{
"idbase": 143057,
"typeemplacement": "Arbre",
"domanialite": "CIMETIERE",
"arrondissement": "PARIS 20E ARRDT",
"complementadresse": null,
"numero": null,
"adresse": "CIMETIERE DU PERE LACHAISE / DIV 41",
"idemplacement": "D00000041050",
"libellefrancais": "Erable",
…
Tous les genres (dans la classification de Linné) :
% jpq '$[*].genre' arbres.json [ "Aesculus", "Crataegus", "Prunus", …
Les sélecteurs par nom peuvent s'écrire avec un point, comme ci-dessus, ou bien entre crochets avec des apostrophes (notez comme c'est moins pratique pour le shell Unix) :
% jpq "\$[*]['genre']" arbres.json [ "Aesculus", "Crataegus", "Prunus", …
La forme avec les crochets est la forme canonique pour une expression JSONPath. La notation avec un point n'est acceptée que pour les noms, pas pour les indices :
% echo '[1, 2, 3]' | jpq '$[1]' [ 2 ] % echo '[1, 2, 3]' | jpq '$.1' Error: × Invalid JSONPath: at position 2, in dot member name, must start with lowercase alpha or '_' ╭──── 1 │ $.1 · ▲ · ╰── in dot member name, must start with lowercase alpha or '_' ╰────
La taille de tous les arbres qui font plus de 50 mètres de haut :
% jpq '$[?@.hauteurenm > 50].hauteurenm' < arbres.json [ 120, 69, 100, 67, 58, 74, 911 ]
L'arobase indique le nœud en cours d'évaluation. Et, oui, l'arbre de 911 mètres de haut est une erreur, chose courante dans les données ouvertes.
Comme vous avez vu, la requête JSONPath renvoie toujours une liste de nœuds, affichée par jpq dans la syntaxe des tableaux JSON.
Vous avez vu, dans l'exemple où on cherchait les plus grands arbres, que JSONPath permet de faire des comparaisons. Vous avez droit à tous les opérateurs booléens classiques. Ici, l'identificateur de tous les arbres situés dans un cimetière :
% jpq '$[?@.domanialite == "CIMETIERE"].idbase' < arbres.json [ 143057, 165296, 166709, …
JSONPath permet d'ajouter des fonctions, qui ne sont utilisables
que pour les comparaisons (je ne crois pas qu'on puisse mettre leur
résultat dans la valeur retournée par JSONPath). Plusieurs d'entre
elles sont définies par ce RFC, comme length(),
mais pas forcément mises en œuvre dans tous les programmes. Et pour
compliquer les choses, des implémentations de JSONPath ajoutent
leurs propres fonctions non enregistrées et qui rendent l'expression
non portable.
Deux de ces fonctions,
search() et match(),
prennent en paramètre une expression
rationnelle, à la syntaxe du RFC 9485.
Les expressions JSONPath, quand on les envoie via l'Internet,
peuvent être marquées avec le type application/jsonpath,
désormais enregistré
(section 3 du RFC). En plus, un
nouveau registre IANA est créé, pour stocker les fonctions
mentionnées au paragraphe précédent. Pour ajouter des fonctions à ce
registre, il faut passer par la procédure « Examen par un expert »
du RFC 8126.
La section 4, sur la sécurité, est très détaillée. JSONPath était souvent mis en œuvre en passant directement l'expression ou une partie d'entre elle au langage sous-jacent (typiquement JavaScript). Inutile de détailler les énormes problèmes de sécurité que cela pose si l'expression évaluée est, en tout ou en partie, fournie par un client externe (par exemple via un formulaire Web), permettant ainsi l'injection de code. Une validation de ces expressions avant de les passer étant irréaliste, le RFC insiste sur le fait qu'une mise en œuvre de JSONPath doit avoir son propre code et ne pas compter sur une évaluation par le langage de programmation sous-jacent.
Même ainsi, une expression JSONPath peut permettre une attaque par déni de service, si une expression mène à une consommation de ressources excessive. (Cf. la section 10 du RFC 8949 et la section 8 du RFC 9485.)
La section 1.2 de notre RFC décrit l'histoire un peu
compliquée de JSONPath. (Une des raisons pour lesquelles il
existe plusieurs langages de requête dans JSON est que JSONPath a
mis du temps à être terminé.) L'origine de JSONPath date de
2007, dans cet article de
Gössner (un des auteurs du RFC). L'interprétation de ce premier
JSONPath était souvent déléguée au langage sous-jacent (le
eval() de JavaScript…)
avec les problèmes de sécurité qu'on imagine. Le JSONPath actuel se
veut portable, au sens où il ne dépend pas d'un langage
d'implémentation particulier, ni d'un moteur
d'expressions rationnelles
particulier. L'inconvénient est qu'il n'est pas forcément compatible
avec l'ancien JSONPath.
JSONPath a aussi été inspiré par le XPath de XML (cf. annexe B de notre RFC, qui détaille cette inspiration, et compare les deux langages). On peut aussi comparer JSONPath à JSON Pointer (RFC 6901), ce qui est fait dans l'annexe C.
Il existe bien sûr d'autres mises en œuvre de JSONPath que jpq. Mais attention : certaines sont très anciennes (comme Python JSONPath RW) et ne correspondent pas à ce qui est normalisé dans le RFC. Essayons Python JSONPath Next-Generation :
% python
Python 3.13.2 (main, Feb 5 2025, 01:23:35) [GCC 14.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from jsonpath_ng.ext import filter, parse
>>> import json
>>> data = json.load(open("arbres.json"))
>>> expr = parse("$[?@.hauteurenm > 50].hauteurenm")
>>> result = expr.find(data)
>>> for r in result:
... print(r.value)
...
120
69
100
67
58
74
911
D'autres langages de requête dans le JSON existent, chacun avec sa syntaxe :
L'article seul
RFC 9609: Initializing a DNS Resolver with Priming Queries
Date de publication du RFC : Février 2025
Auteur(s) du RFC : P. Koch (DENIC
eG), M. Larson, P. Hoffman
(ICANN)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 12 février 2025
Un résolveur DNS ne connait au début, rien du contenu du DNS. Rien ? Pas tout à fait, il connait une liste des serveurs de noms faisant autorité pour la racine, car c'est par eux qu'il va commencer le processus de résolution de noms. Cette liste est typiquement en dur dans le code du serveur, ou bien dans un de ses fichiers de configuration. Mais peu d'administrateurs système la maintiennent à jour. Il est donc prudent, au démarrage du résolveur, de chercher une liste vraiment à jour, et c'est le priming (amorçage, comme lorsqu'on amorce une pompe pour qu'elle fonctionne seule ensuite), opération que décrit ce RFC, qui remplace l'ancienne version, le RFC 8109 (les changements sont nombreux mais sont surtout des points de détail).
Le problème de départ d'un résolveur est un problème d'œuf et de
poule. Le résolveur doit interroger le DNS pour avoir
des informations mais comment trouve-t-il les serveurs DNS à
interroger ? La solution est de traiter la racine du DNS de manière
spéciale : la liste de ses serveurs est connue du résolveur au
démarrage. Elle peut être dans le code du serveur lui-même, ici un
Unbound qui contient les adresses IP des
serveurs de la racine (je ne montre que les trois premiers,
A.root-servers.net,
B.root-servers.net et
C.root-servers.net) :
% strings /usr/sbin/unbound | grep -i 2001: 2001:503:ba3e::2:30 2001:500:84::b 2001:500:2::c ...
Ou bien elle est dans un fichier de configuration (ici, sur un Unbound) :
server: directory: "/etc/unbound" root-hints: "root-hints"
Ce fichier peut être téléchargé via
l'IANA, il peut être spécifique au logiciel résolveur, ou bien fourni
par le système d'exploitation (cas du
paquetage dns-root-data chez
Debian). Il contient la liste des serveurs
de la racine et leurs adresses :
. 3600000 NS A.ROOT-SERVERS.NET. . 3600000 NS B.ROOT-SERVERS.NET. ... A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4 A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30 B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201 B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b ...
Tous les résolveurs actuels mettent en œuvre le priming. En effet, les configurations locales tendent à ne plus être à jour au bout d'un moment. (Sauf dans le cas où elles sont dans un paquetage du système d'exploitation, mis à jour avec ce dernier, comme dans le bon exemple Debian ci-dessus.)
Les changements des serveurs racines sont rares. Si on regarde sur le site des opérateurs des serveurs racine, on voit :
- 2017-08-10 B-Root's IPv4 address to be renumbered on 2017-10-24
- 2016-12-02 Announcement of IPv6 addresses
- 2015-11-05 L-Root IPv6 Renumbering
- 2015-08-31 H-Root to be renumbered
- 2014-03-26 IPv6 service address for c.root-servers.net (2001:500:2::C)
- 2012-12-14 D-Root IPv4 Address to be Renumbered
Bref, peu de changements. Ils sont en général annoncés sur les listes de diffusion opérationnelles (comme ici). Mais les fichiers de configuration ayant une fâcheuse tendance à ne pas être mis à jour et à prendre de l'âge, les anciennes adresses des serveurs racine continuent à recevoir du trafic des années après (comme le montre cette étude de J-root). Notez que la stabilité de la liste des serveurs racine n'est pas due qu'au désir de ne pas perturber les administrateurs système : il y a aussi des raisons politiques (aucun mécanisme en place pour choisir de nouveaux serveurs, ou pour retirer les « maillons faibles »). C'est pour cela que la liste des serveurs (mais pas leurs adresses) n'a pas changé depuis 1997 ! (Une histoire - biaisée - des serveurs racine a été publiée par l'ICANN.)
Notons aussi que l'administrateur système d'un résolveur peut changer la liste des serveurs de noms de la racine pour une autre liste, par exemple s'ielle veut utiliser une racine alternative.
Le priming, maintenant. Le principe du priming est, au démarrage, de faire une requête à un des serveurs listés dans la configuration et de garder sa réponse (certainement plus à jour que la configuration) :
% dig +bufsize=4096 +norecurse +nodnssec @i.root-servers.net . NS ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> +bufsize +norecurse +nodnssec @i.root-servers.net . NS ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54419 ;; flags: qr aa; QUERY: 1, ANSWER: 13, AUTHORITY: 0, ADDITIONAL: 27 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ; COOKIE: c0a47c1200bf6bfc0100000067377b40981cc05cdb33b736 (good) ;; QUESTION SECTION: ;. IN NS ;; ANSWER SECTION: . 518400 IN NS k.root-servers.net. . 518400 IN NS h.root-servers.net. . 518400 IN NS m.root-servers.net. . 518400 IN NS l.root-servers.net. . 518400 IN NS b.root-servers.net. . 518400 IN NS e.root-servers.net. . 518400 IN NS d.root-servers.net. . 518400 IN NS f.root-servers.net. . 518400 IN NS g.root-servers.net. . 518400 IN NS i.root-servers.net. . 518400 IN NS a.root-servers.net. . 518400 IN NS j.root-servers.net. . 518400 IN NS c.root-servers.net. ;; ADDITIONAL SECTION: m.root-servers.net. 518400 IN A 202.12.27.33 l.root-servers.net. 518400 IN A 199.7.83.42 k.root-servers.net. 518400 IN A 193.0.14.129 j.root-servers.net. 518400 IN A 192.58.128.30 i.root-servers.net. 518400 IN A 192.36.148.17 h.root-servers.net. 518400 IN A 198.97.190.53 g.root-servers.net. 518400 IN A 192.112.36.4 f.root-servers.net. 518400 IN A 192.5.5.241 e.root-servers.net. 518400 IN A 192.203.230.10 d.root-servers.net. 518400 IN A 199.7.91.13 c.root-servers.net. 518400 IN A 192.33.4.12 b.root-servers.net. 518400 IN A 170.247.170.2 a.root-servers.net. 518400 IN A 198.41.0.4 m.root-servers.net. 518400 IN AAAA 2001:dc3::35 l.root-servers.net. 518400 IN AAAA 2001:500:9f::42 k.root-servers.net. 518400 IN AAAA 2001:7fd::1 j.root-servers.net. 518400 IN AAAA 2001:503:c27::2:30 i.root-servers.net. 518400 IN AAAA 2001:7fe::53 h.root-servers.net. 518400 IN AAAA 2001:500:1::53 g.root-servers.net. 518400 IN AAAA 2001:500:12::d0d f.root-servers.net. 518400 IN AAAA 2001:500:2f::f e.root-servers.net. 518400 IN AAAA 2001:500:a8::e d.root-servers.net. 518400 IN AAAA 2001:500:2d::d c.root-servers.net. 518400 IN AAAA 2001:500:2::c b.root-servers.net. 518400 IN AAAA 2801:1b8:10::b a.root-servers.net. 518400 IN AAAA 2001:503:ba3e::2:30 ;; Query time: 6 msec ;; SERVER: 192.36.148.17#53(i.root-servers.net) (UDP) ;; WHEN: Fri Nov 15 17:48:00 CET 2024 ;; MSG SIZE rcvd: 851
(Les raisons du choix des trois options données à dig sont indiquées plus loin.)
La section 3 de notre RFC décrit en détail à quoi ressemblent les
requêtes de priming. Le type de données demandé
(QTYPE) est NS (Name Servers,
type 2) et le nom demandé (QNAME) est « . » (oui,
juste la racine). D'où le dig . NS
ci-dessus. Le bit RD (Recursion Desired) est
typiquement mis à zéro (d'où le +norecurse dans
l'exemple avec dig). La taille de la réponse dépassant les 512
octets (limite très ancienne du DNS), il faut utiliser
EDNS (cause du
+bufsize=4096 dans l'exemple). On peut utiliser
le bit DO (DNSSEC OK) qui indique qu'on demande
les signatures DNSSEC mais ce n'est pas habituel (d'où le
+nodnssec dans l'exemple). En effet, si la
racine est signée, permettant d'authentifier l'ensemble
d'enregistrements NS, la zone root-servers.net,
où se trouvent actuellement tous les serveurs de la racine, ne l'est
pas, et les enregistrements A et AAAA ne peuvent donc pas être
validés avec DNSSEC.
Cette requête de priming est envoyée lorsque le résolveur démarre, et aussi lorsque la réponse précédente a expiré (regardez le TTL dans l'exemple : six jours). Si le premier serveur testé ne répond pas, on essaie avec un autre. Ainsi, même si le fichier de configuration n'est pas parfaitement à jour (des vieilles adresses y trainent), le résolveur finira par avoir la liste correcte.
Et comment choisit-on le premier serveur qu'on interroge ? Notre RFC recommande (section 3.2) un tirage au sort, pour éviter que toutes les requêtes de priming ne se concentrent sur un seul serveur (par exemple le premier de la liste). Une fois que le résolveur a démarré, il peut aussi se souvenir du serveur le plus rapide, et n'interroger que celui-ci, ce qui est fait par la plupart des résolveurs, pour les requêtes ordinaires (mais n'est pas conseillé pour le priming).
Et les réponses au priming ? Il faut bien
noter que, pour le serveur racine, les requêtes
priming sont des requêtes comme les autres, et ne
font pas l'objet d'un traitement particulier. Normalement, la
réponse doit avoir le code de retour NOERROR
(c'est bien le cas dans mon exemple). Parmi les
flags, il doit y avoir AA (Authoritative
Answer). La section de réponse doit évidemment contenir
les NS de la racine, et la section additionnelle les adresses IP. Le
résolveur garde alors cette réponse dans son cache, comme il le
ferait pour n'importe quelle autre réponse. Notez que là aussi, il
ne faut pas de traitement particulier. Par exemple, le résolveur ne
doit pas compter sur le fait qu'il y aura exactement 13 serveurs,
même si c'est le cas depuis longtemps (ça peut changer).
Normalement, le serveur racine envoie la totalité des adresses IP
(deux par serveur, une en IPv4 et une en
IPv6). S'il ne le fait pas (par exemple par
manque de place parce qu'on a bêtement oublié
EDNS), le résolveur va devoir envoyer des
requêtes A et AAAA explicites pour obtenir les adresses IP (ici, on
interroge k.root-servers.net) :
% dig @2001:7fd::1 g.root-servers.net AAAA ; <<>> DiG 9.18.33-1~deb12u2-Debian <<>> @2001:7fd::1 g.root-servers.net AAAA ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10640 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ;; QUESTION SECTION: ;g.root-servers.net. IN AAAA ;; ANSWER SECTION: g.root-servers.net. 3600000 IN AAAA 2001:500:12::d0d ;; Query time: 3 msec ;; SERVER: 2001:7fd::1#53(2001:7fd::1) (UDP) ;; WHEN: Thu Feb 13 17:26:51 CET 2025 ;; MSG SIZE rcvd: 75
Vous pouvez voir ici les requêtes et réponses de priming d'un Unbound. D'abord, décodées par tcpdump :
17:57:14.439382 IP (tos 0x0, ttl 64, id 26437, offset 0, flags [none], proto UDP (17), length 56)
10.10.156.82.51893 > 198.41.0.4.53: [bad udp cksum 0x6cbf -> 0x49dc!] 63049% [1au] NS? . ar: . OPT UDPsize=1232 DO (28)
17:57:14.451715 IP (tos 0x40, ttl 52, id 45305, offset 0, flags [none], proto UDP (17), length 1125)
198.41.0.4.53 > 10.10.156.82.51893: [udp sum ok] 63049*- q: NS? . 14/0/27 . [6d] NS l.root-servers.net., . [6d] NS j.root-servers.net., . [6d] NS f.root-servers.net., . [6d] NS h.root-servers.net., . [6d] NS d.root-servers.net., . [6d] NS b.root-servers.net., . [6d] NS k.root-servers.net., . [6d] NS i.root-servers.net., . [6d] NS m.root-servers.net., . [6d] NS e.root-servers.net., . [6d] NS g.root-servers.net., . [6d] NS c.root-servers.net., . [6d] NS a.root-servers.net., . [6d] RRSIG ar: l.root-servers.net. [6d] A 199.7.83.42, l.root-servers.net. [6d] AAAA 2001:500:9f::42, j.root-servers.net. [6d] A 192.58.128.30, j.root-servers.net. [6d] AAAA 2001:503:c27::2:30, f.root-servers.net. [6d] A 192.5.5.241, f.root-servers.net. [6d] AAAA 2001:500:2f::f, h.root-servers.net. [6d] A 198.97.190.53, h.root-servers.net. [6d] AAAA 2001:500:1::53, d.root-servers.net. [6d] A 199.7.91.13, d.root-servers.net. [6d] AAAA 2001:500:2d::d, b.root-servers.net. [6d] A 170.247.170.2, b.root-servers.net. [6d] AAAA 2801:1b8:10::b, k.root-servers.net. [6d] A 193.0.14.129, k.root-servers.net. [6d] AAAA 2001:7fd::1, i.root-servers.net. [6d] A 192.36.148.17, i.root-servers.net. [6d] AAAA 2001:7fe::53, m.root-servers.net. [6d] A 202.12.27.33, m.root-servers.net. [6d] AAAA 2001:dc3::35, e.root-servers.net. [6d] A 192.203.230.10, e.root-servers.net. [6d] AAAA 2001:500:a8::e, g.root-servers.net. [6d] A 192.112.36.4, g.root-servers.net. [6d] AAAA 2001:500:12::d0d, c.root-servers.net. [6d] A 192.33.4.12, c.root-servers.net. [6d] AAAA 2001:500:2::c, a.root-servers.net. [6d] A 198.41.0.4, a.root-servers.net. [6d] AAAA 2001:503:ba3e::2:30, . OPT UDPsize=4096 DO (1097)
Et ici par tshark :
1 0.000000 10.10.156.82 → 198.41.0.4 DNS 70 Standard query 0xf649 NS <Root> OPT 2 0.012333 198.41.0.4 → 10.10.156.82 DNS 1139 Standard query response 0xf649 NS <Root> NS l.root-servers.net NS j.root-servers.net NS f.root-servers.net NS h.root-servers.net NS d.root-servers.net NS b.root-servers.net NS k.root-servers.net NS i.root-servers.net NS m.root-servers.net NS e.root-servers.net NS g.root-servers.net NS c.root-servers.net NS a.root-servers.net RRSIG A 199.7.83.42 AAAA 2001:500:9f::42 A 192.58.128.30 AAAA 2001:503:c27::2:30 A 192.5.5.241 AAAA 2001:500:2f::f A 198.97.190.53 AAAA 2001:500:1::53 A 199.7.91.13 AAAA 2001:500:2d::d A 170.247.170.2 AAAA 2801:1b8:10::b A 193.0.14.129 AAAA 2001:7fd::1 A 192.36.148.17 AAAA 2001:7fe::53 A 202.12.27.33 AAAA 2001:dc3::35 A 192.203.230.10 AAAA 2001:500:a8::e A 192.112.36.4 AAAA 2001:500:12::d0d A 192.33.4.12 AAAA 2001:500:2::c A 198.41.0.4 AAAA 2001:503:ba3e::2:30 OPT
Et un décodage plus détaillé de tshark dans ce fichier.
Enfin, la section 6 de notre RFC traite des problèmes de sécurité du priming. Évidemment, si un attaquant injecte une fausse réponse aux requêtes de priming, il pourra détourner toutes les requêtes ultérieures vers des machines de son choix. À part le RFC 5452, et l'utilisation de cookies (RFC 7873, mais seuls les serveurs racine C, F, G et I les gèrent aujourd'hui), la seule protection est DNSSEC : si le résolveur valide (et a donc la clé publique de la racine), il pourra détecter que les réponses sont mensongères (voir aussi la section 3.3). Cela a l'avantage de protéger également contre d'autres attaques, ne touchant pas au priming, comme les attaques sur le routage.
Notez que DNSSEC est recommandé pour valider les réponses
ultérieures mais, comme on l'a vu, n'est pas important pour valider
la réponse de priming elle-même, puisque
root-servers.net n'est pas signé. Si un
attaquant détournait, d'une manière ou d'une autre, vers un faux
serveur racine, servant de fausses données, ce ne serait qu'une
attaque par déni de
service, puisque le résolveur validant pourrait détecter
que les réponses sont fausses.
L'annexe A du RFC liste les changements depuis le RFC 8109. Rien de vraiment crucial, juste une longue liste de clarifications et de précisions.
L'article seul
Fiche de lecture : Rose Valland - l'espionne à l'œuvre
Auteur(s) du livre : Jennifer Lesieur
Éditeur : Robert Laffont
978-2-253-24937-5
Publié en 2023
Première rédaction de cet article le 10 février 2025
Rose Valland n'est évidemment plus une inconnue. Néanmoins, son nom et son activité m'avaient échappé et c'est grâce à ce petit livre que j'ai appris son rôle, pendant et après la guerre, pour documenter les pillages d'œuvres d'art, et essayer d'en récupérer le plus grand nombre.
Grâce au film Monuments Men, ce pillage d'œuvres d'art par les nazis en Europe occupée, et le travail de récupération des œuvres est bien connu. Mais Hollywood se focalise sur le rôle des États-Unis, alors que des pays qui n'ont pas la même puissance médiatique sont moins mentionnés. En France, Rose Valland, conservatrice de musée, a joué pourtant un rôle important. Pendant l'Occupation, elle notait tout, les œuvres d'art enlevées, les noms des voleurs, les destinations des trains qui pouvaient permettre d'identifier les dépôts en Allemagne. À la Libération, elle a accompagné les troupes alliées en Allemagne et ses notes ont beaucoup contribué à retrouver un grand nombre de tableaux ou de sculptures et à les rapporter au bon endroit.
Ce court livre raconte la vie de Rose Valland, de conservatrice de musée binoclarde et réservée, à aventurière en jeep dans une Allemagne dévastée, à chercher des milliers d'œuvres d'art. Une vie passionnante, face à d'innombrables difficultés. Toustes les résistant·es n'avaient pas forcément une arme à feu…
L'article seul
Faut-il critiquer l'IA ?
Première rédaction de cet article le 9 février 2025
Plusieurs organisations françaises viennent de signer un appel critique vis-à-vis de l'IA, dans le contexte du sommet IA du gouvernement. Alors que je suis en général d'accord avec ces organisations, cet appel me semble frapper à côté de la cible, car il attribue à l'IA un rôle excessif.
À l'approche du sommet IA, les discours technobéats se multiplient, affirmant que l'IA va tout résoudre et qu'il faut vite y investir des milliards de gigawatts pour rester compétitif. Les injonctions à passer à l'IA, à accélérer le déploiement de l'IA jusque dans nos brosses à dent, évidemment connectées, sont répétées sans cesse. Face à ce délire marketing et politicien, on comprend l'agacement des gens qui tiennent à garder un regard critique sur le numérique. (Rappel : « critique » au sens de « penser par soi-même, sans forcément suivre le discours dominant », pas au sens de « jamais d'accord ».) Cet agacement peut mener à passer complètement de l'autre côté et à dire que l'IA ne sert à rien, voire qu'elle est 100 % néfaste.
Mais l'appel dont je parlais a un autre défaut : il met l'IA à toutes les sauces. Par exemple quand il dit que « elle [l'IA] est le plus souvent imposée sans réelle prise en compte de ses impacts délétères sur les droits humains » comme si ce n'était pas le cas de tout le numérique (cf. par exemple le RFC 8280), et même de toutes les innovations techniques. À lire l'appel, on a l'impression que les choses allaient plus ou moins bien avant mais que l'IA a entrainé une rupture qualitative. Ce qui est, paradoxalement, exactement le discours des techno-béats qui promeuvent l'IA à tout prix.
Qu'on attribue à l'IA des miracles ou au contraire qu'on l'accuse de tous les maux, dans les deux cas, on fait l'erreur de croire qu'il existe bien quelque chose qui s'appellerait « l'IA » et qui aurait des caractéristiques qui en feraient quelque chose de très distinct du reste du monde numérique. En réalité, « IA » est un terme surtout marketing, sans définition précise, et qui a surtout une longue histoire dans la communication plus que dans la technique. (Notons qu'« algorithme » est également souvent utilisé mal à propos mais ce mot, au moins, a une définition rigoureuse.) Alors, oui, les LLM existent, oui, les logiciels de génération de textes ou d'images ont fait des très gros progrès depuis quelques années, des nouvelles techniques et des nouveaux outils sont développés par les chercheur·ses, mais il n'est pas du tout évident que cela change fondamentalement les questions qu'on se posait déjà avant que ChatGPT ne remette l'IA à la mode.
Par exemple, quand l'appel de Hiatus dit « dans l’action publique, elle [l'IA] agit en symbiose avec les politiques d’austérité qui sapent la justice socio-économique », c'est très discutable alors qu'on n'a pas attendu l'IA pour casser les services publics, souvent au nom de la dématérialisation (je recommande par exemple l'excellent rapport de la Défenseure des Droits sur l'ANEF).
Bref, autant la critique du numérique est indispensable, autant je pense que c'est une mauvaise idée que d'ériger « l'IA » en phénomène spécifique.
L'article seul
Articles des différentes années : 2025 2024 2023 2022 2021 2020 2019 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}